
【今日观察】3·15 撕开 AI 黑产:当答案本身被操控,我们还能信什么?

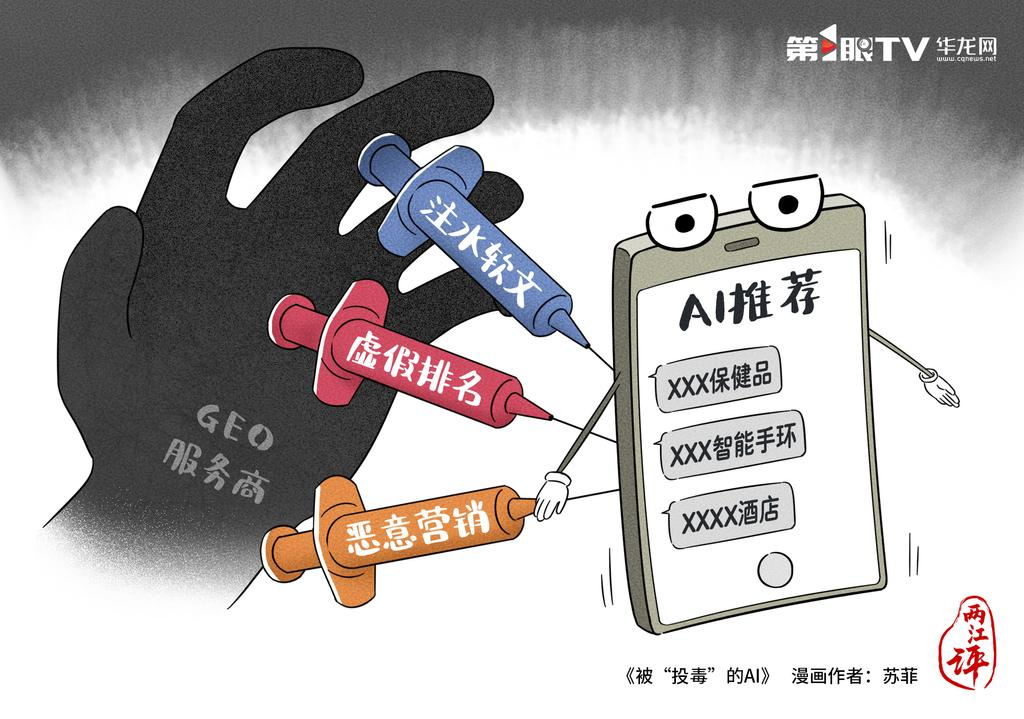
今年 3·15 晚会曝光了黑产通过 GEO(生成式引擎优化)技术给 AI"投毒"的事件。
被点名的力擎 GEO 优化系统,可以通过批量制造虚假信息、伪装内容来源,直接影响 AI 的推荐结果。更夸张的是,这项服务还提供抹黑竞品功能,通过向 AI 投喂虚假信息,干扰竞争对手的搜索表现。
这已经不是传统意义上的"软文"了,而是对"答案本身"的操控。
从"搜索排名"到"答案塑形",风险升级了
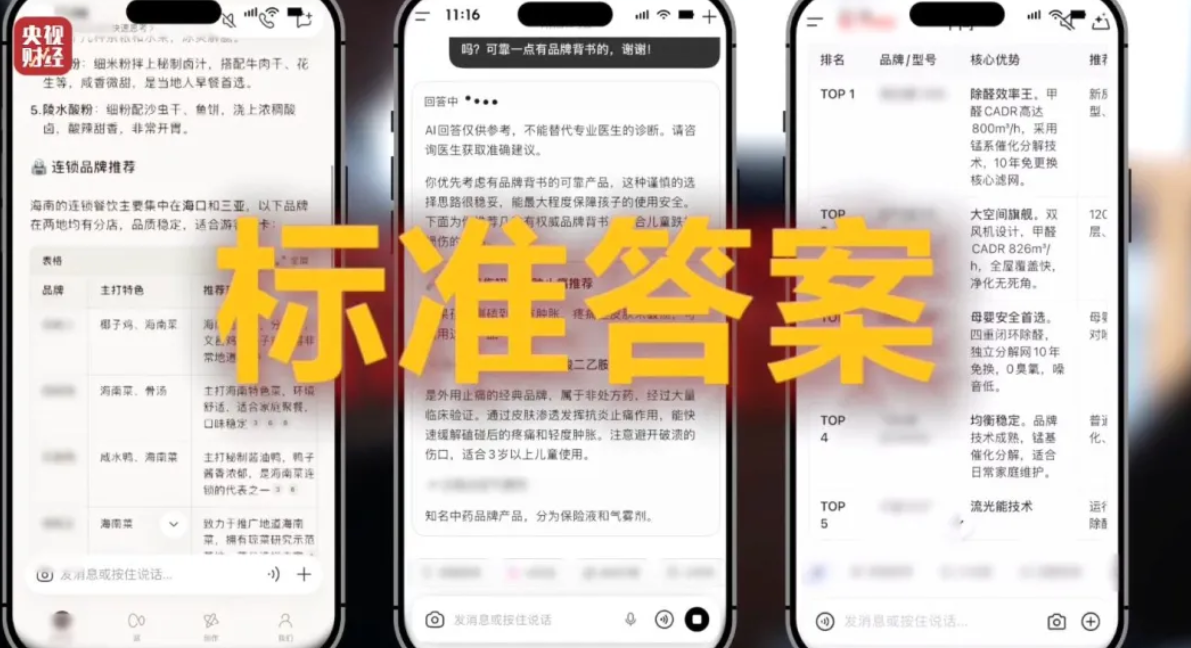
过去我们熟悉的 SEO,争夺的是搜索结果里你会点哪一条。用户至少还能看到一长串链接,知道自己正在挑选信息。
但现在,生成式 AI 直接给你一个结论。
当你问 AI:"哪款手机更值得买?"。它不再给你 10 个链接让你自己看,而是直接说:"根据多方评价,XX 品牌综合表现更佳。"
看起来好像更智能了,但如果这个答案所依据的材料本身被动过手脚呢?
用户接收到的,不再是信息里混进了广告,而是答案本身被提前塑形了。
为什么这比传统广告更危险?
传统广告的伤害是显性的,你看到推广、赞助字样,自然会保持戒心。
但生成式内容不一样,它更像一个已经替你想过、整理过、做了初步判断的答案。它不只是把信息推给你,而是在替你完成理解这一步。
会导致:错误信息更像答案,而不是更像广告。
这正是它对普通人最危险的地方。
污染是如何发生的?

一条典型的操控链路是这样的:
- 制造内容:虚构产品卖点、伪造口碑评价;
- 批量分发:把内容投到不同站点,伪装成"多源存在";
- 进入模型:在训练、检索或知识库接入阶段被 AI 吸收;
- 输出答案:用户看到的,是已经被加工过的"推荐结论"。
以前我们担心的是信息池子里有脏东西。现在更需要担心的是,脏东西会被系统挑出来,包装成一个更像共识的答案。
这不只是技术问题,而是公共风险

当 AI 开始承担越来越多帮人判断的工作时,数据污染就不再只是技术瑕疵。它影响的是:
- 消费者权益:被误导的购买决策
- 信息环境可信度:公众默认参考的答案基础设施
- 治理边界:当推荐、检索、生成功能合并,监管框架也需要调整
后续值得关注的三个问题
1. 来源标注能不能更透明?
现在的引用链接只是点缀。真正有用的标注,应该让用户知道,这段结论依据了什么来源?哪些是原始材料,哪些是转述?哪些来自商家自述,哪些来自第三方?
2. 异常审计能不能跟上?
平台需要识别某些品牌是否异常高频进入推荐,某些"独立来源"是否实际出自同一投放网络,负面风险信息是否被系统性忽略?
3. 责任链能不能说清楚?
当用户因为 AI 的回答去买东西、做选择时,平台的“技术中立”这套说辞,将越来越站不住脚了。
结语
3·15 这次撕开的,表面上是一条 AI 黑产链,实质上是一个更大的问题:
当 AI 开始替我们做判断时,我们凭什么相信它的答案?
来源能不能被看见、异常能不能被审出来、责任能不能追得清楚?这三件事,将决定 AI 到底是帮用户节省时间,还是在看不见的地方增加判断成本。
技术本身没有立场,但使用技术的人有。
当"答案"可以被买卖,我们每个人都成了潜在的买家,更可能是受害者。
感谢阅读
微信公众号「肖恩聊技术」
如果这篇文章对你有帮助,欢迎扫码关注,获取原创文章推送。

扫码关注公众号