
AI Agent初体验:变革正悄然发生
2022年12月OpenAI推出ChatGPT,经过2023一整年迭代和各方势力追赶,在24年迎来了集体的爆发。各式各样的工具层出不穷,从最开始的聊天机器人,到AI写作工具、AI图像工具、AI视频工具、AI幻灯片工具和AI编程工具等等。好像任何和内容创作相关的场景都可以和大模型挂钩,都能产生“化学反应”。

AI经历了三次发展浪潮,这次是第三次高峰。技术的变革会经过多次的震荡,但每一次发展浪潮都会让更多的泡沫破灭,使得下次的发展达到更高的高度。作为本次浪潮必将被波及的人员,是时候全面拥抱AI了,早点入局能掌握更多主动性,万一这次真实现 AGI(通用人工智能)了呢。

相关概念
大模型(Large Language Model)
大型语言模型(Large Language Model),通常指的是在机器学习和人工智能领域,尤其是深度学习领域中,参数数量非常多的模型。这些模型因为拥有大量的参数,能够捕捉和学习到数据中的复杂模式和关系。

大模型的一些关键特点:
① 参数数量:大模型通常拥有数百万甚至数十亿个参数,这些参数在训练过程中不断调整以更好地拟合数据;

GPT-4参数约1.76T
GPT-4o参数约200B
GPT-4o mini参数约8B
o1-preview参数约300B
o1-mini参数约100B
Claude 3.5 Sonnet参数约175B
DeepSeek-V3参数约为671B,激活37B
PS:1B"的全称是"1 Billion",表示十亿。② 计算资源需求:由于参数众多,大模型需要大量的计算资源,包括高性能的GPU或TPU等硬件加速器;
③ 数据需求:为了训练这些模型,需要大量的数据来确保模型的泛化能力,避免过拟合。
④ 复杂性:大模型能够处理更复杂的任务,如自然语言处理(NLP)、计算机视觉(CV)等,并且通常在这些任务上表现更好。

- 语言大模型(NLP):是指在自然语言处理领域中的一类大模型,通常用于处理文本数据和理解自然语言。这类大模型的主要特点是它们在大规模语料库上进行了训练,以学习自然语言的各种语法、语义和语境规则。

视觉大模型(CV):是指在计算机视觉领域中使用的大模型,通常用于图像处理和分析。这类模型通过在大规模图像数据上进行训练,可以实现各种视觉任务,如图像分类、目标检测、图像分割、姿态估计、人脸识别等。
多模态大模型:是指能够处理多种不同类型数据的大模型,例如文本、图像、音频等多模态数据。这类模型结合了 NLP 和 CV 的能力,以实现对多模态信息的综合理解和分析,从而能够更全面地理解和处理复杂的数据。
⑤ 泛化能力:是指一个模型在面对新的、未见过的数据时,能够正确理解和预测这些数据的能力。理论上,参数更多的模型具有更强的泛化能力,能够在未见过的数据上表现良好。
⑥ 可扩展性:大模型可以通过增加参数数量来扩展,以适应更复杂的任务或提高性能。
⑦ 研究和应用:大模型在学术研究和工业应用中都非常受欢迎,它们推动了许多领域的技术进步。
⑧ 成本:训练和部署大模型的成本相对较高,这限制了它们的普及。
⑨ 环境影响:大模型的训练和运行可能会消耗大量的能源,对环境产生影响。
扩展阅读:原来用初中数学就能看懂大语言模型的奥秘
虽然LLM很强大,但当前市面上的模型仍有缺陷,主要问题有:
- 信息偏差/幻觉
- 知识更新滞后性
- 内容不可追溯
- 领域专业知识能力欠缺
- 推理能力限制
- 应用场景适应性受限
- 长文本处理能力较弱
其中热度较高的问题——幻觉,即生成的内容与可验证的真实世界事实不一致,或者偏离用户指令或提供的上下文信息。
幻觉产的原因有多个:
- 训练数据的局限性:LLM是基于大量文本数据训练的,但这些数据可能会存在偏差、错误或过时的信息。
- 模型结构的限制:尽管LLM非常强大,但它们本质上是基于统计模式的预测模型,无法真正”理解”信息。
- 上下文理解不充分:LLM可能无法准确把握复杂的上下文关系,导致生成不恰当的内容。
- 过度泛化:模型可能会过度依赖某些模式,导致在新情况下产生错误的推断。
- 缺乏实时更新:LLM通常是基于静态数据训练的,无法及时获取最新信息。
一般缓解幻觉的方法有:
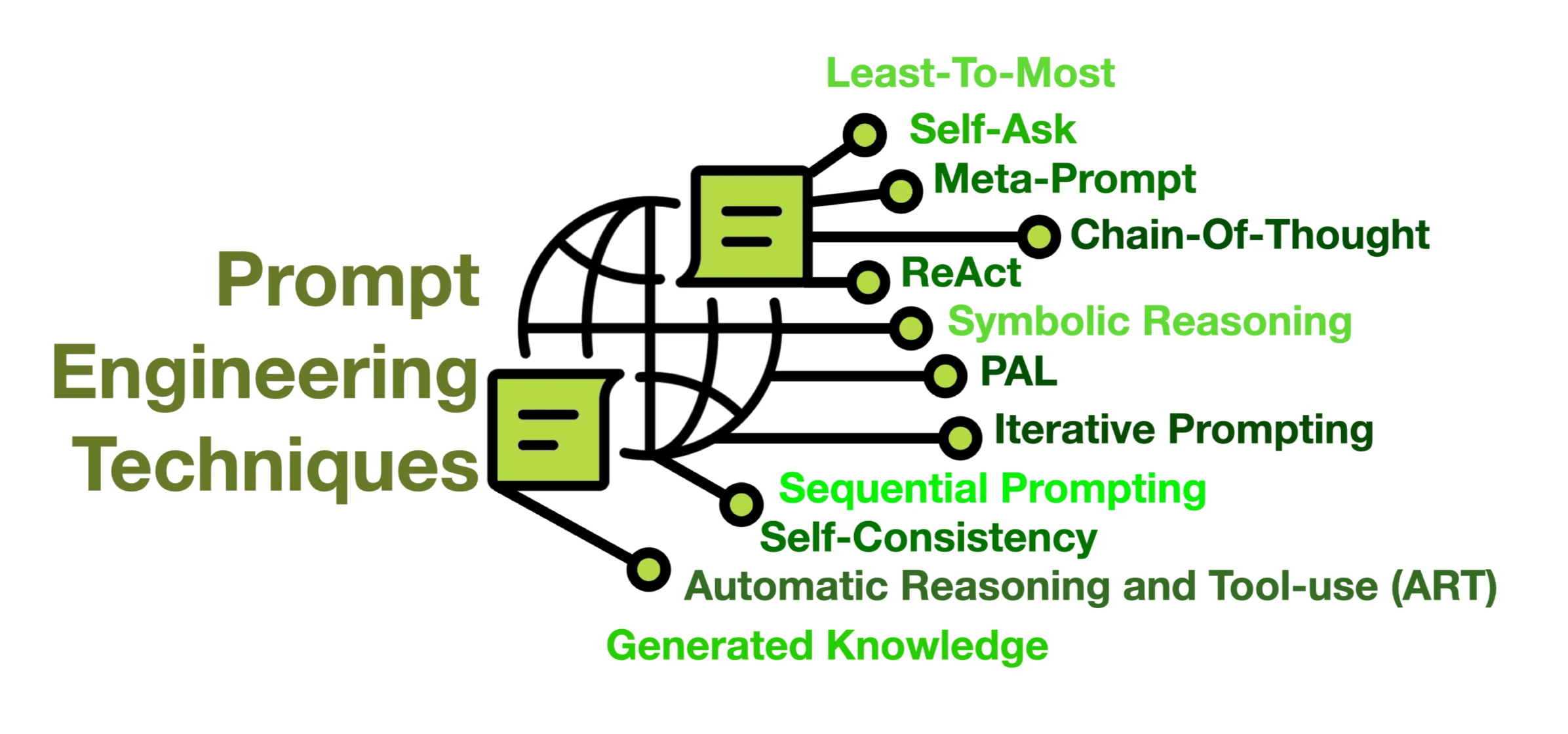
- 提示工程(Prompt Engineering)
就是那些如雷贯耳的名词:Prompt、RAG、反馈机制。相关概念和技术比较多,大家感兴趣可以自行检索一下或阅读提示工程指南。
- 模型开发(Developing Models)
从模型架构和训练过程上改善,一般是更多的参数、更好的数据质量。一些关键词:解码策略 、知识图谱 、监督微调等。

智能体(AI Agent)
智能体(Intelligent Agent)是一个计算机科学和人工智能领域的概念,它指的是一个能够感知其环境并作出行动以实现某些目标或任务的系统。智能体可以是软件或硬件,或者是两者的结合。

大模型智能体是一种基于大型语言模型(LLM)构建的智能体,它具备环境感知能力、自主理解、决策制定及执行行动的能力。这种智能体能够模拟独立思考过程,灵活调用各类工具,逐步达成预设目标。在技术架构上,大模型智能体从面向过程的架构转变为面向目标的架构,旨在通过感知、思考与行动的紧密结合,完成复杂任务。
AI Agent = LLM + Planning + Feedback + Tool use
大模型智能体可以理解为各种技术的综合应用,运用的技术(RAG、提示词工程、知识库和实时检索等)能在一定程度上弥补大模型的缺陷,提升生成内容质量。其核心组成部分包括感知(perception)、大脑(brain)和行动(action),更细化的构成有:
① 感知系统(Perception):
- 传感器输入:智能体通过传感器收集环境信息,如视觉、声音、触觉等。
- 数据预处理:对收集到的数据进行清洗、标准化等处理,以便于进一步分析。
② 认知系统(Cognition):
- 大模型:核心的人工智能模型,能够处理和理解感知系统收集的数据。
- 知识库:存储相关的知识信息,供智能体进行推理和决策。
- 推理引擎:基于逻辑和规则进行推理,以形成决策或解决问题。
③ 记忆系统(Memory):
- 短期记忆:存储当前任务相关的信息。
- 长期记忆:存储历史数据和经验,用于学习和模式识别。
④ 决策系统(Decision Making):
- 策略生成:根据感知和认知的结果,生成可能的行动方案。
- 优化算法:选择最佳行动方案,可能涉及多目标优化、强化学习等技术。
⑤ 行动系统(Action):
- 执行器:将决策转化为实际的物理动作或指令。
- 反馈机制:执行后的结果反馈给感知系统,形成闭环控制。
⑥ 学习系统(Learning):
- 监督学习:通过标记数据学习特定任务。
- 无监督学习:在没有明确标记的情况下发现数据中的模式。
- 强化学习:通过与环境的交互学习最优策略。
⑦ 交互系统(Interaction):
- 自然语言处理:理解和生成自然语言,与人类或其他智能体交流。
- 多模态交互:结合视觉、听觉等多种感官信息进行交互。
⑧ 伦理和安全系统(Ethics and Safety):
- 伦理决策:确保智能体的决策符合伦理标准。
- 安全监控:监控智能体的行为,防止潜在的安全风险。
⑨ 用户界面(User Interface):
- 可视化界面:为用户提供直观的操作界面。
- 交互设计:设计用户与智能体交互的方式。
⑩ 硬件平台(Hardware Platform):
- 计算资源:提供必要的计算能力,如GPU、TPU等。
- 存储资源:存储模型、数据和结果。
一些常见的智能体和智能体构建平台(来源 awesome-ai-agents):

国内智能体构建平台举例:

扩展阅读:Building effective agents (Claude官方:构建高效的智能体指南)
实践案例
搜索智能体
顾名思义,就是能够帮你自动检索并总结相关内容的智能体。如果你不擅长信息检索,苦于找不到技术问题或方案的解决思路,那么它可以成为你获取信息的第一步。
易用性:⭐️⭐️⭐️⭐️⭐️
中文:Kimi 探索版
具备 AI 自主搜索能力,可以模拟人类的推理思考过程,多级分解复杂问题,执行深度搜索,并即时反思改进结果,提供更全面和准确的答案,帮助你更高效地完成分析调研等复杂任务。

英文:Storm
STORM 是一个利用大型语言模型(LLM)的系统,能够从互联网搜索中撰写类似维基百科的文章。核心在于自动提出好问题,它采用了两种策略来提高问题的深度和广度:视角引导的问题提问和模拟对话。


问答智能体
这里特指私有知识库问答智能体,能在理解相关资料的前提下总结核心知识点,并基于已有知识给出回答。
易用性:⭐️⭐️⭐️⭐️
底层核心技术包括提示词和RAG。提示词的好坏对结果的生成质量影响很大。
一个优秀的 Prompt = 角色 + 场景 + 任务 + 输出要求RAG(检索增强生成)是一个将输入与一组相关的支持文档结合起来的技术,这些文档通常来自于像维基百科这样的来源。这些文档被添加到输入提示中,一起送入文本生成器,从而产生最终的输出。

Ollama+AnythingLLM搭建本地知识库
Ollama 是一个免费的开源项目,是一个专为在本地机器上便捷部署和运行 LLM 而设计的开源工具,可在本地运行各种开源 LLM,它让用户无需深入了解复杂的底层技术,就能轻松地加载、运行和交互各种LLM模型。
AnythingLLM 是一个全栈应用程序,可以使用商业现成的 LLM 或流行的开源 LLM 和 vectorDB 解决方案来构建私有 ChatGPT。可以在本地运行,也可以远程托管。能够在智能聊天中检索提供的任何文件。
下面简单介绍一下搭建步骤:
① 本地大模型安装
- 安装 ollama
- 安装 llama
ollama run llama3.2
- 服务器模式启动大模型
ollama serve
② 搭建本地LLM交互界面
- 安装 anythingllm

- 模型配置

- 导入本地文档

- 开始智能问答

PS:回答的效果依赖大模型的质量,参数越多的大模型对硬件条件要求更大,大家量力而行。
编程智能体
编程智能体是利用LLM来辅助编程的工具,能提供代码自动生成、补全、翻译、注释添加、智能问答等功能,以提高开发效率和代码质量。网上有一些偏激的言论:“AI 智能体终将取代现有的程序员岗位!”。
易用性:⭐️⭐️⭐️
提供哪些功能:
- 自动化编码
- 代码补全和建议
- 静态代码分析
- 代码性能分析
- 代码重构
- 测试用例生成
受限于大模型上下文长度限制,目前对于一些复杂场景表现较差。但随着大模型能力越来越强,会越来越接近较多开发者水平,并在知识广度上更具优势。
Cline:开源编程智能体插件
Cline 是一个开源项目!集成在 IDE中的自主编码智能体,它能够使用命令行界面(CLI)和编辑器来自动化软件开发任务。
Cline 通过集成大模型编码能力,可以逐步处理复杂的软件开发任务,包括创建和编辑文件、探索大型项目、使用浏览器以及执行终端命令。还可以使用模型上下文协议(MCP)来创建新工具并扩展其功能。Cline 提供了一个人工智能的图形用户界面(GUI),用于确认每个文件更改和终端命令,提供了一个安全且易于访问的方式来探索AI智能体的潜力。
下面简单介绍安装和配置:
① VSCode中安装Cline插件

② 大模型Key配置
大模型推荐使用DeepSeek-V3,国产开源,物美价廉,生成效果堪比主流闭源(吃草挤奶)。


③ 扩展配置
主要是文件读取、编辑,命令执行,浏览器和MCP等使用权限设置。

下面来看一下两个使用案例:
案例1:2048小游戏
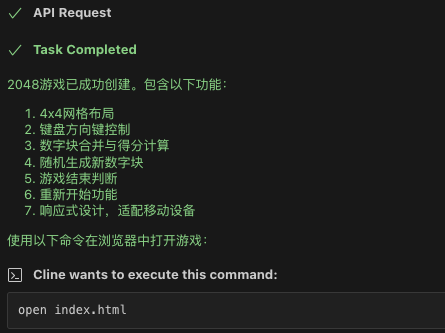
- 描述需求并等待编码完成

- 任务完成信息
- 生成效果查看

- 提交修改意见并等待编码完成

- 验收效果

案例2:代码重构 & 单侧生成
- 打开已有代码或项目并提交重构诉求

- 提交单侧生成诉求


- 基于运行报错修改单侧代码

将报错信息对话框发送给Cline用于修改代码。
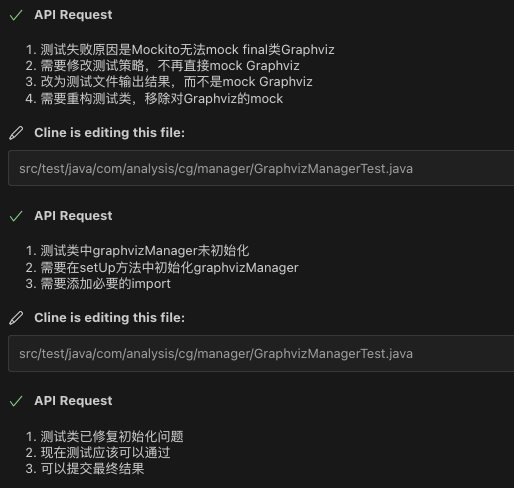
- 运行单侧

Cursor:超火的AI代码编辑器
Cursor 是一款基于人工智能的代码编辑器,创建了一个集成开发环境(IDE)。旨在帮助开发人员编写代码,并于AI进行实时互动,提供写代码建议、错误检测和自动补全功能。支持多种编程语言(如Python、JavaScript、Java等)。
案例:根据图片生成前端页面
- 提供一张图片并填写诉求

- 代码自动生成


- 运行查看效果

真的,除了价格都挺美丽。

启示
既见未来,为何不拜。

感谢阅读
微信公众号「肖恩聊技术」
如果这篇文章对你有帮助,欢迎扫码关注,获取原创文章推送。

扫码关注公众号