
省流总结:
LLM之所以能“知道”应调用哪个MCP服务及其参数,并不是源自模型本身具备实时解析接口的能力,而是依赖于智能体框架在运行时自动收集、整理所有可用服务的描述和参数定义(schema)。
这些结构化信息通过特定的Prompt或函数调用协议作为上下文注入LLM。LLM基于用户输入和这些服务信息推理出是否需要发起服务调用,并以标准化格式(如JSON)输出调用指令和参数。
框架再解析LLM输出并完成实际调用,并将结果返回给大模型进行后续处理。

2025/5/26大约 5 分钟
省流总结:
LLM之所以能“知道”应调用哪个MCP服务及其参数,并不是源自模型本身具备实时解析接口的能力,而是依赖于智能体框架在运行时自动收集、整理所有可用服务的描述和参数定义(schema)。
这些结构化信息通过特定的Prompt或函数调用协议作为上下文注入LLM。LLM基于用户输入和这些服务信息推理出是否需要发起服务调用,并以标准化格式(如JSON)输出调用指令和参数。
框架再解析LLM输出并完成实际调用,并将结果返回给大模型进行后续处理。
面试中问到 TCP 相关知识时一般会问到三次握手和四次挥手,内容大家一定回答过很多次并熟记于心了。传统的 TCP 建立连接时需要三次握手,并且握手时只发送简单的 SYN 和 ACK 报文(部分优化的网络协议栈可以在第三次握手时直接发送数据)。
从网络带宽的资源利用的角度来看,传输层的 TCP 头部 + 网络层的 IP 头部,最少有 40 个字节,为了发送几个字节的报文数据包,而额外组装了 40 个字节的头部,着实有点浪费资源。
从应用优化的角度来看,因为要等到 TCP 经过三次握手建立连接之后才能发送应用层数据,所以会造成应用程序首次发送数据时存在一定的延迟,尤其是短连接、移动设备等场景中,这种副作用会加剧。
为解决上述问题,TCP Fast Open 应运而生。
编译器:将用编程语言(源语言)编写的计算机代码翻译成另一种语言(目标语言)的计算机程序。
编译程序以高级程序源代码作为输入,以汇编语言或机器语言表示的目标程序作为输出。目标程序会在机器上运行,得到所需的结果。编译器可能执行以下操作:预处理、词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成。
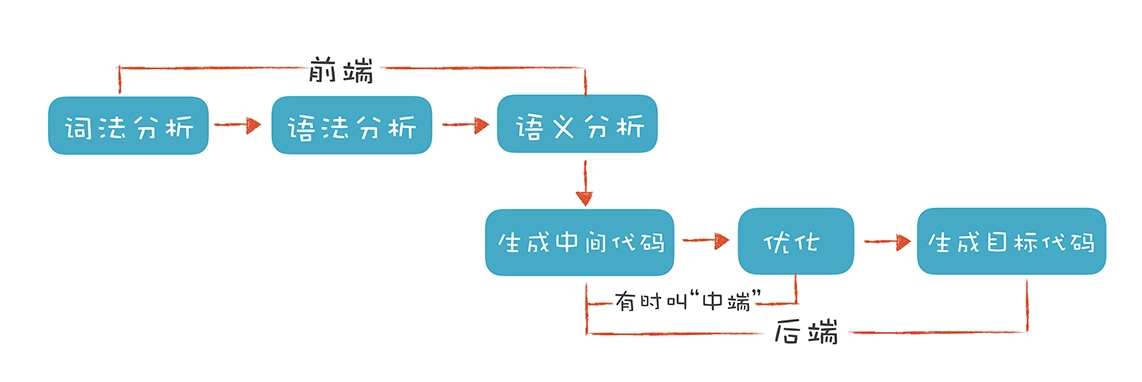
编译器前端和中端理论知识与代码可视化的实现最为相关,后端部分和目标机器代码、特定机器架构相关一般很少用到可视化中。
在开发过程中,每一次的代码改动都可能对程序的运行结果造成影响。越早评估出改动的影响面将更容易把风险扼杀在摇篮里,以更小的成本避免事故的发生。先用2个常见的开发场景来还原描述为什么我们需要“代码变更影响分析”:

Code visualization is the process of creating graphical representations of source code to help understand and analyze it.
代码可视化是创建源代码的图形表示以帮助理解和分析它的过程。
个人理解:通过使用图形化手段(架构图、依赖图、分布式追踪、类图、火焰图、CallGraph等)使代码在某些特征上变得可观测,用于辅助开发人员理解分析项目或建设一些自动化工具。