1. 编译器概述
编译器:将用编程语言(源语言)编写的计算机代码翻译成另一种语言(目标语言)的计算机程序。
编译程序以高级程序源代码作为输入,以汇编语言或机器语言表示的目标程序作为输出。目标程序会在机器上运行,得到所需的结果。编译器可能执行以下操作:预处理、词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成。
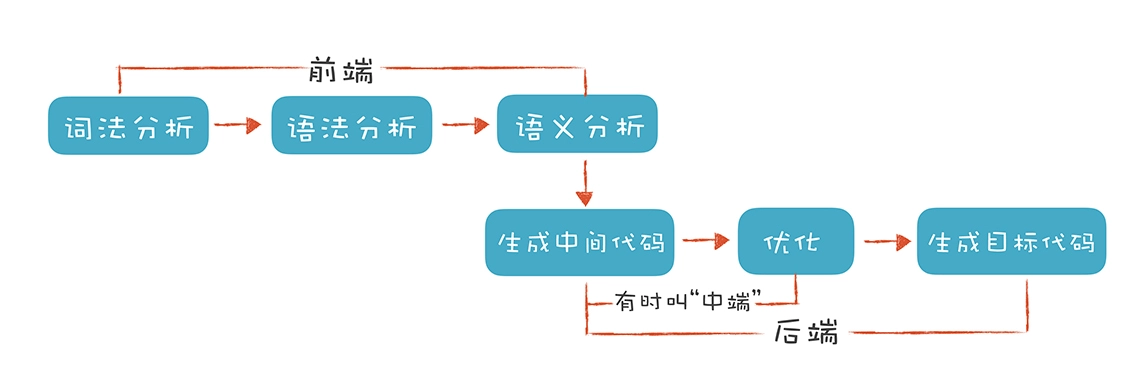
编译器前端和中端理论知识与代码可视化的实现最为相关,后端部分和目标机器代码、特定机器架构相关一般很少用到可视化中。
2. 语法分析(Syntactic Analysis, or Parsing)
语法分析又称解析(parsing),它在词法分析后执行。将tokens组织成语法结构,通常是一棵抽象语法树(Abstract Syntax Tree, AST),这棵树表示了源代码的语法结构。语法分析器需要根据一组预定义的语法规则来分析词法单元序列。这些规则通常以上下文无关文法(Context-Free Grammar, CFG)的形式定义,其中每个规则定义了语言中的一个结构如何由其他结构组成。
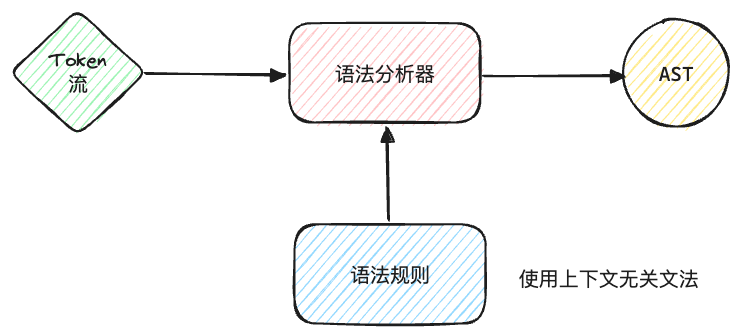
这里先简单说一下CFG,如果想深入学习可以再查查资料。一个上下文无关文法由以下四个部分组成:
- ① 非终结符(Non-terminals):这些是文法的变量,表示一组字符串的集合。它们通常用大写字母表示,如A,B,Expr等;
- ② 终结符(Terminals):这些是文法的基本符号,它们构成了语言的字符串。在编程语言中,终结符可以是关键字、操作符、标识符等。它们通常用小写字母、数字或其他符号表示;
- ③ 产生式规则(Production rules):这些规则定义了非终结符如何被终结符或其他非终结符的序列替换。规则的形式通常是A → B C,表示非终结符A可以被B C替换;
- ④ 开始符号(Start symbol):这是一个特殊的非终结符,用于表示整个语言或文法的起始点。
举个栗子:
S → a S b
S → ε
-------解释--------
·非终结符是S
·终结符是a和b
·产生式规则有两条:S → a S b 表示 S 可以被 a S b 替换,S → ε 表示 S 可以被空字符串替换(ε 表示空字符串)
·开始符号是S
这个文法生成的语言是所有a和b的平衡字符串,例如:ab、aabb、aaabbb 等。
语法分析的核心能力是给定文法G和句子s,回答s是否能够从G推导出来。实现的方式可以大致分为自底向上和自顶向下的语法分析:
- ① 自顶向下语法分析:从树的顶部(即开始符号)开始构建解析树的过程。在这种方法中,解析器尝试找出输入字符串可以从哪个产生式开始,并逐步展开这些产生式,直到获得完整的输入字符串。自顶向下解析的特点是直观、易于实现,尤其是对于简单的文法。然而,它们可能无法处理左递归文法,且对于复杂的文法可能不够高效。常见的算法有“递归下降解析”和“LL解析”,算法的详细过程这里就不分析了,大家可以查查资料或者问一下GPT。
- ② 自底向上语法分析:从树的底部(即输入字符串)开始构建解析树的过程。在这种方法中,解析器尝试找出输入字符串的哪些部分可以对应文法的某个产生式的右侧,并将其规约为产生式的左侧,逐步减少整体的长度,直到最终规约为开始符号。自底向上解析通常比自顶向下解析更强大,因为它们可以处理更复杂的文法,包括那些自顶向下解析器无法处理的文法。然而,它们的解析表通常更为复杂,且实现起来可能更为困难。常见的算法有“LR解析”。
3. 使用Antlr语法分析
了解了基本概念后我们还是练练手,使用Antlr对Java源码进行语法分析。这次就不使用grammars-v4中定义的语法规则了,因为编程语言的语法规则比较复杂最后生成的AST可读性比较差。
- 语法规则定义(词法规则定义:CommonLexer.g4,语法规则定义:PlayScript.g4)
grammar PlayScript;
import CommonLexer; //导入词法定义
/*下面的内容加到所生成的Java源文件的头部,如包名称,import语句等。*/
@header {
package antlrtest;
}
expression
: assignmentExpression
| expression ',' assignmentExpression
;
assignmentExpression
: additiveExpression
| Identifier assignmentOperator additiveExpression
;
assignmentOperator
: '='
| '*='
| '/='
| '%='
| '+='
| '-='
;
additiveExpression
: multiplicativeExpression
| additiveExpression '+' multiplicativeExpression
| additiveExpression '-' multiplicativeExpression
;
multiplicativeExpression
: primaryExpression
| multiplicativeExpression '*' primaryExpression
| multiplicativeExpression '/' primaryExpression
| multiplicativeExpression '%' primaryExpression
;
- 使用Antlr生成语法分析器并执行分析操作
# ① 编译语法规则
antlr PlayScript.g4
# ② 编译上一步生成的java文件(注意需要把Antlr的JAR文件设置到CLASSPATH环境变量,否则会报错)
javac *.java
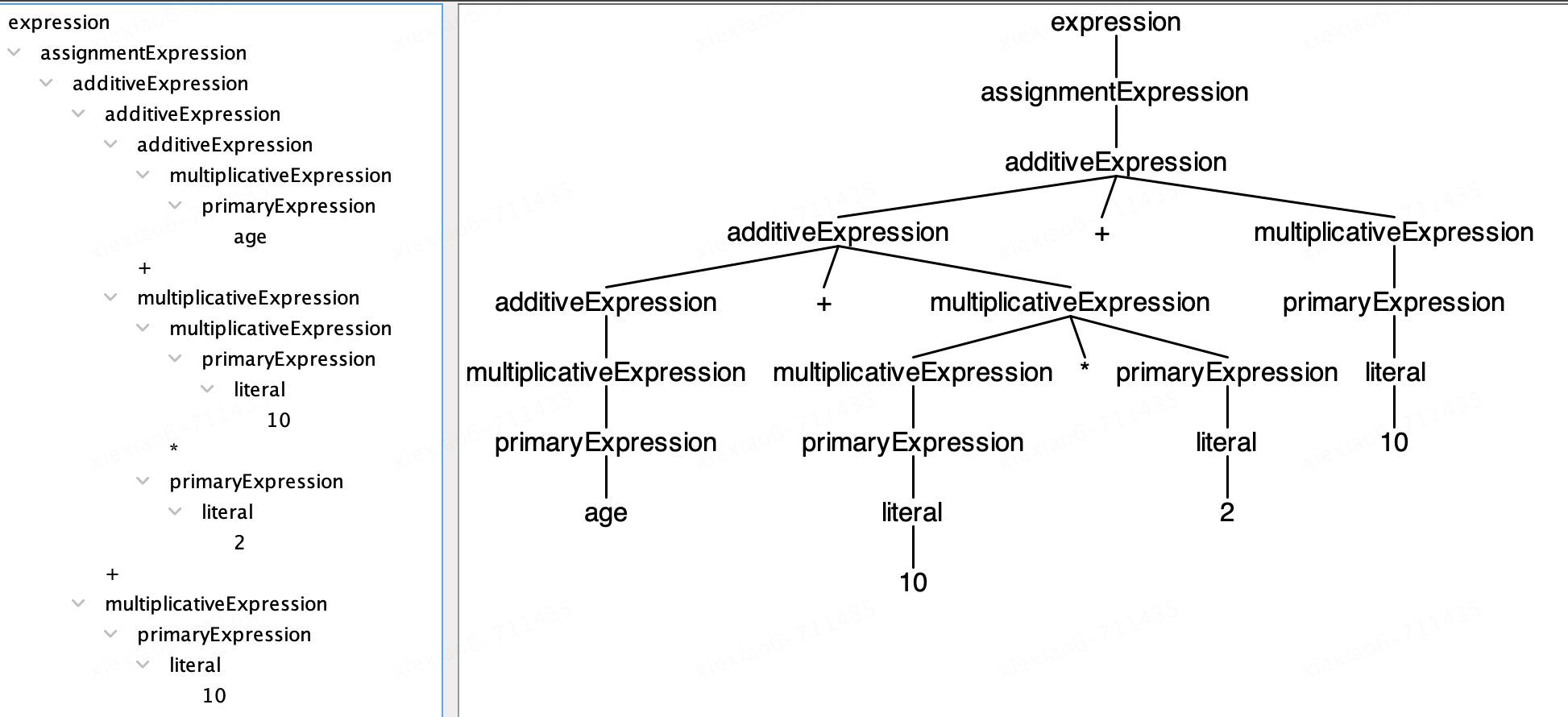
# ③ 调用生成的语法分析器获取分析结果(输入表达式后使用^D触发AST图生成)
grun antlrtest.PlayScript expression -gui
age + 10 * 2 + 10
^D