1. 编译器概述
编译器:将用编程语言(源语言)编写的计算机代码翻译成另一种语言(目标语言)的计算机程序。
编译程序以高级程序源代码作为输入,以汇编语言或机器语言表示的目标程序作为输出。目标程序会在机器上运行,得到所需的结果。编译器可能执行以下操作:预处理、词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成。
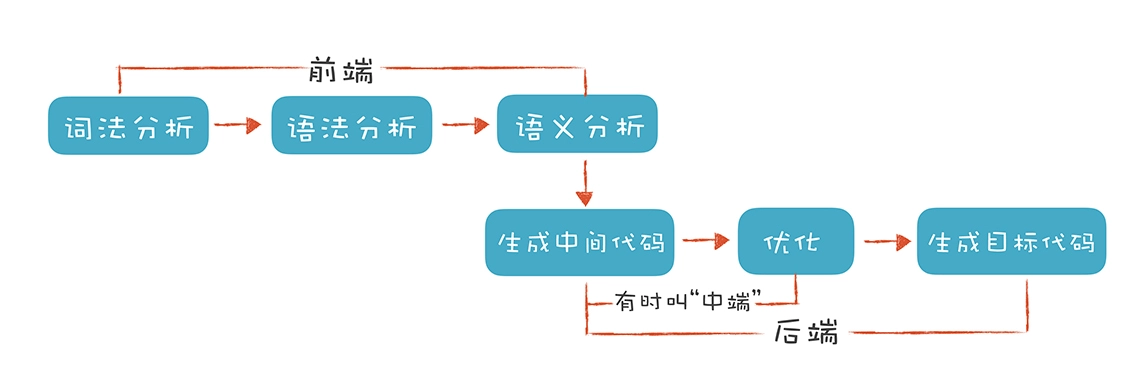
编译器前端和中端理论知识与代码可视化的实现最为相关,后端部分和目标机器代码、特定机器架构相关一般很少用到可视化中。
2. 词法分析(Lexical Analysis,or Scanning)
词法分析又称扫描(scanning),通过读入组成源程序的字符流,将它们组织成为有意义的词素(lexeme)的序列。词素是源程序中的最小语言单位,如关键字、标识符、常数、操作符和分隔符等。对于每个词素,词法分析器将产生对应的词法单元(token)作为输出。
token:<种别码,属性值>

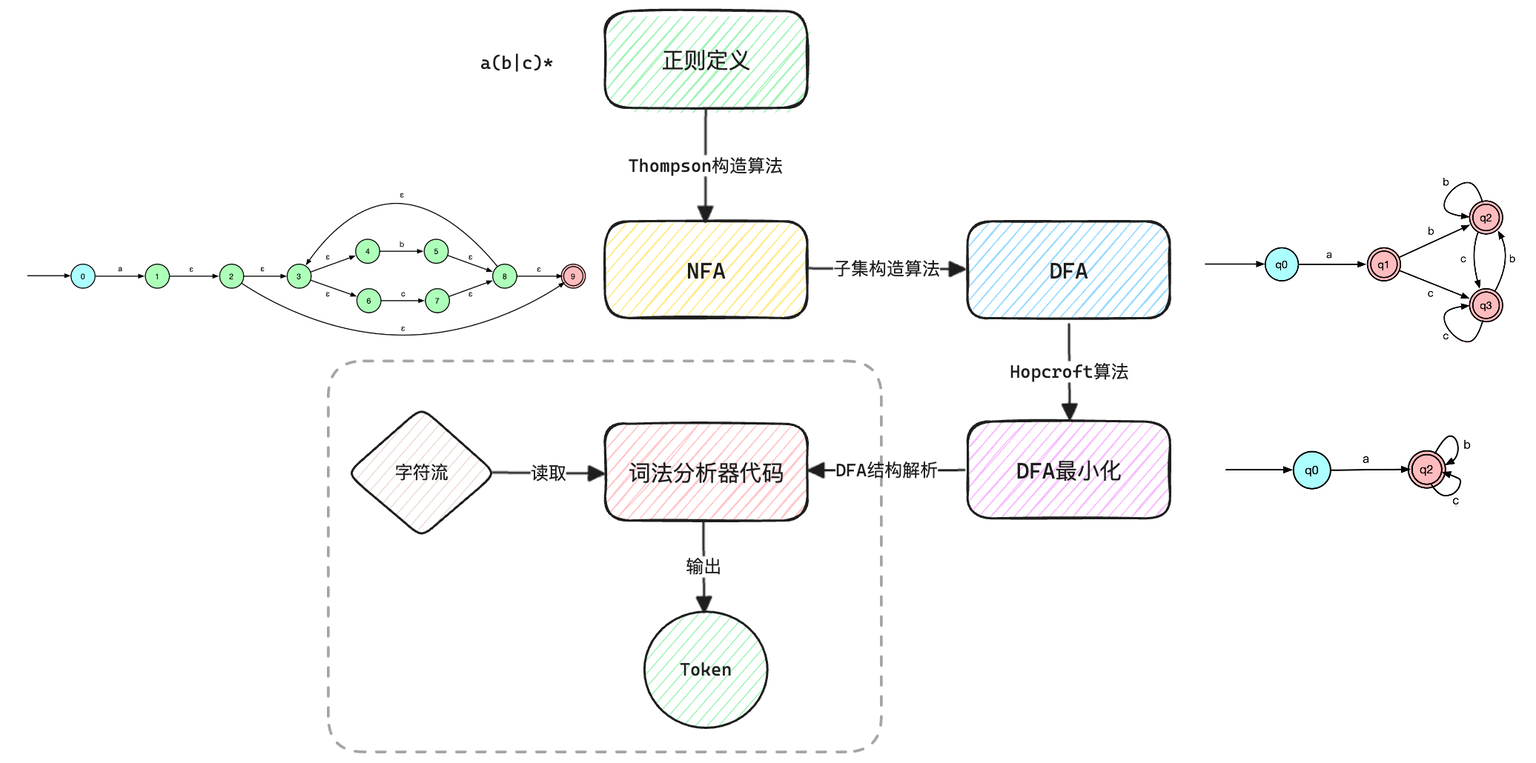
词法分析器的核心逻辑基于有限自动机(Finite Automata),可以理解为有限个状态的自动执行机器,用来将扫描得到的字符映射到有限个的可能性上。类型包括:
- 不确定性有限自动机(NFA):在某状态和输入符号下可能存在多个可能的转移状态;
- 确定性有限自动机(DFA):在任何状态和输入符号下都只有一个唯一的转移状态。
整个自动构造过程见下图,大致了解一下即可,如果想深入学习各种算法细节可自行查阅资料。
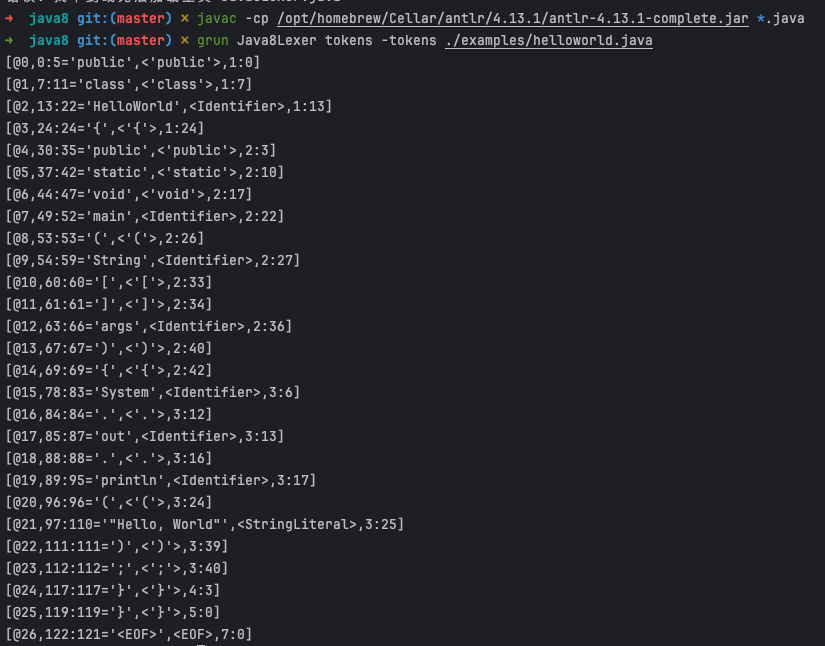
3. 使用Antlr词法分析
接下来我们练练手,使用Antlr对Java源码进行词法分析。Antlr是一个开源工具,支持根据规则文件生成词法分析器和语法分析器,它自身是用 Java 实现的,Mac上可以使用Homebrew安装或者直接使用idea插件antlr-v4。同时grammars-v4上提供了很多供参考的规则,我们这里也直接使用其中针对Java8定义的词法分析规则练手。
- 词法规则定义:Java8Lexer.g4
- 关键字定义
ABSTRACT : 'abstract';
ASSERT : 'assert';
BOOLEAN : 'boolean';
BREAK : 'break';
BYTE : 'byte';
CASE : 'case';
CATCH : 'catch';
CHAR : 'char';
...
- 字符串字面量定义
StringLiteral: '"' StringCharacters? '"';
fragment StringCharacters: StringCharacter+;
fragment StringCharacter: ~["\\\r\n] | EscapeSequence;
...
- 待解析的Java代码
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World");
}
}
- 使用Antlr生成词法分析器并执行分析操作
# ① 编译词法规则
antlr Java8Lexer.g4
# ② 编译上一步生成的java文件(注意需要把Antlr的JAR文件设置到CLASSPATH环境变量,否则会报错)
javac Java8Lexer.java
# ③ 调用生成的词法分析器获取分析结果
grun Java8Lexer tokens -tokens ./examples/helloworld.java