本文最早撰写于4月,当时效果一般且工具JoyCode未开放外网因此文章也未发布。经过8个月的发展,编程智能体有了很大进步,越来越可用,生成的效果也越来越好。因此在新工具上执行了文章中相关案例,重新整理发布一下。
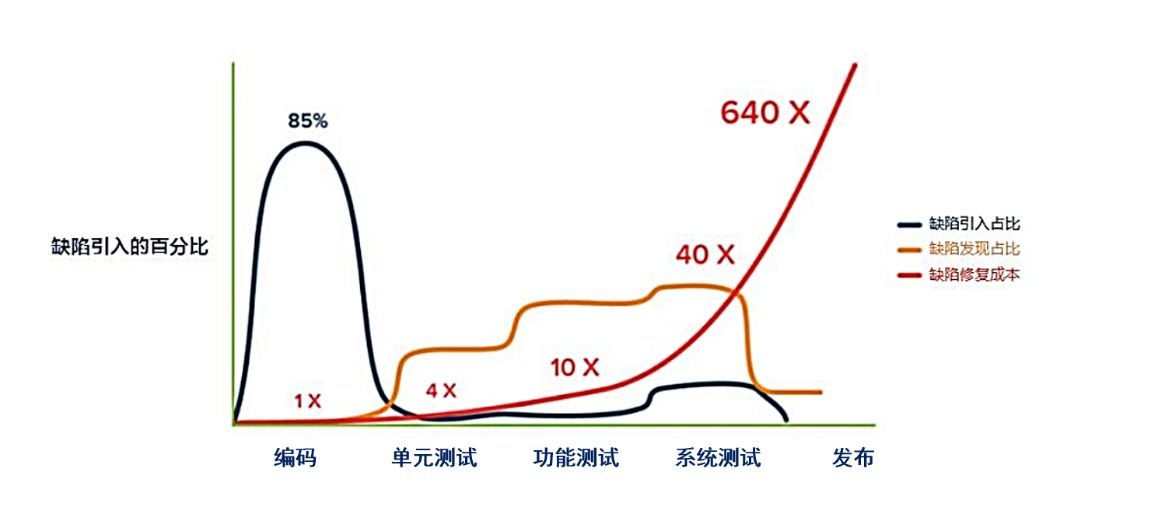
XML之父Tim Bray有个好玩的说法:“代码不写测试就像上了厕所不洗手……单元测试是对软件未来的一项必不可少的投资。” 从下图可以了解到85%的缺陷都在编码阶段产生,而发现Bug的阶段越靠后,修复成本就越高,而且是指数级别的增高!
从缺陷修复成本出发,单元测试的含金量不言而喻。
单元测试
什么是单测?
单元测试是软件开发过程中不可或缺的一部分,它通过验证代码的最小可测试单元(如函数、方法或类)的正确性,确保代码在开发、维护和重构过程中保持高质量和稳定性。
单测的价值
- 更快地发现问题
- 性价比最高
- 提升系统健壮性
- 有利于需求稳定迭代
- 提高前后端联调效率
- 提升代码编写能力
- 有利于深入了解技术与业务
如何写好单侧?
好的测试长什么样?
一个好的测试首先应该是简单的,否则我们无法保证测试的正确性。
① 基本结构
@Test
public void should_add_todo_item() {
// 准备
TodoItemRepository repository = mock(TodoItemRepository.class);
when(repository.save(any())).then(returnsFirstArg());
TodoItemService service = new TodoItemService(repository);
// 执行
TodoItem item = service.addTodoItem(new TodoParameter("foo"));
// 断言
assertThat(item.getContent()).isEqualTo("foo");
// 清理(可选)
}- 准备:为测试做一些准备,比如启动外部依赖的服务,存储一些预置的数据等
- 执行:整个测试最核心的部分,触发被测目标的行为。测试点在大多数情况下,应该就是一个函数调用。如果是测试外部系统,就是发出一个请求
- 断言:断言是测试预期,负责验证执行的结果是否正确。比如,被测系统是否返回了正确的应答
- 清理:清理是可选部分。如果在测试中使用了外部资源,要及时地释放掉,保证测试环境还原到最初的状态。比如,我们在测试过程中向数据库插入了数据,执行之后,要删除测试过程中插入的数据
② 衡量标准(A-TRIP)
- 自动化(Automatic):测试要有断言,在有断言的情况下,机器才能判断测试是否成功
- 全面(Thorough):尽可能用测试覆盖各种场景
- 可重复(Repeatable):测试能反复运行且结果一致,这是保证测试简单可靠的前提
- 独立(Independent):测试之间不应该有任何依赖,测试不能依赖于另外一个测试运行的结果
- 专业(Professional):测试代码也是代码,要按照代码的标准去维护,比如良好的命名、把函数写小、重构甚至抽象出测试基础库和模式
什么样的代码适合写单测?
单测目的是验证代码最小可测试单元(如函数、方法或类)的正确性,并不是所有代码都适合编写单测。因此不要盲目的追求高覆盖率,要结合实际情况考虑,优先添加高ROI的单测。
① 代码编写建议
TDD的核心思想是在编写实际功能代码之前,先编写测试代码,通过测试来驱动设计和实现。但在实际工作中很难彻底落实TDD,一方面是编码习惯的改变会带来新的工作量,另一方面是大多数情况下是在已有项目上新增逻辑会受历史因素影响。
虽然不用像TDD做的那么极限,但在新代码编写时也需要考虑代码的可测试性,从而编写出适合测试的代码。下面是一些建议:
- 模块化:将代码划分为小的、独立的模块,每个模块完成单一功能
- 依赖注入:避免在类内部直接创建依赖对象,而是通过构造函数或参数注入依赖项,便于测试时替换
- 单一职责:确保每个类或方法只负责一项职责,简化测试用例的设计
- 纯函数:尽量编写纯函数(输入相同则输出相同,无副作用)
- 抽离依赖:将外部依赖(如数据库、API调用)抽象为接口,测试时可用Mock替代
- 避免全局状态:减少全局变量或静态变量,防止测试间的副作用
- 清晰的接口:定义明确的接口,便于测试验证行为
- 可观察性:确保代码的行为(输出、日志、事件等)可以被外部观察到,以便验证
② 评估单测ROI
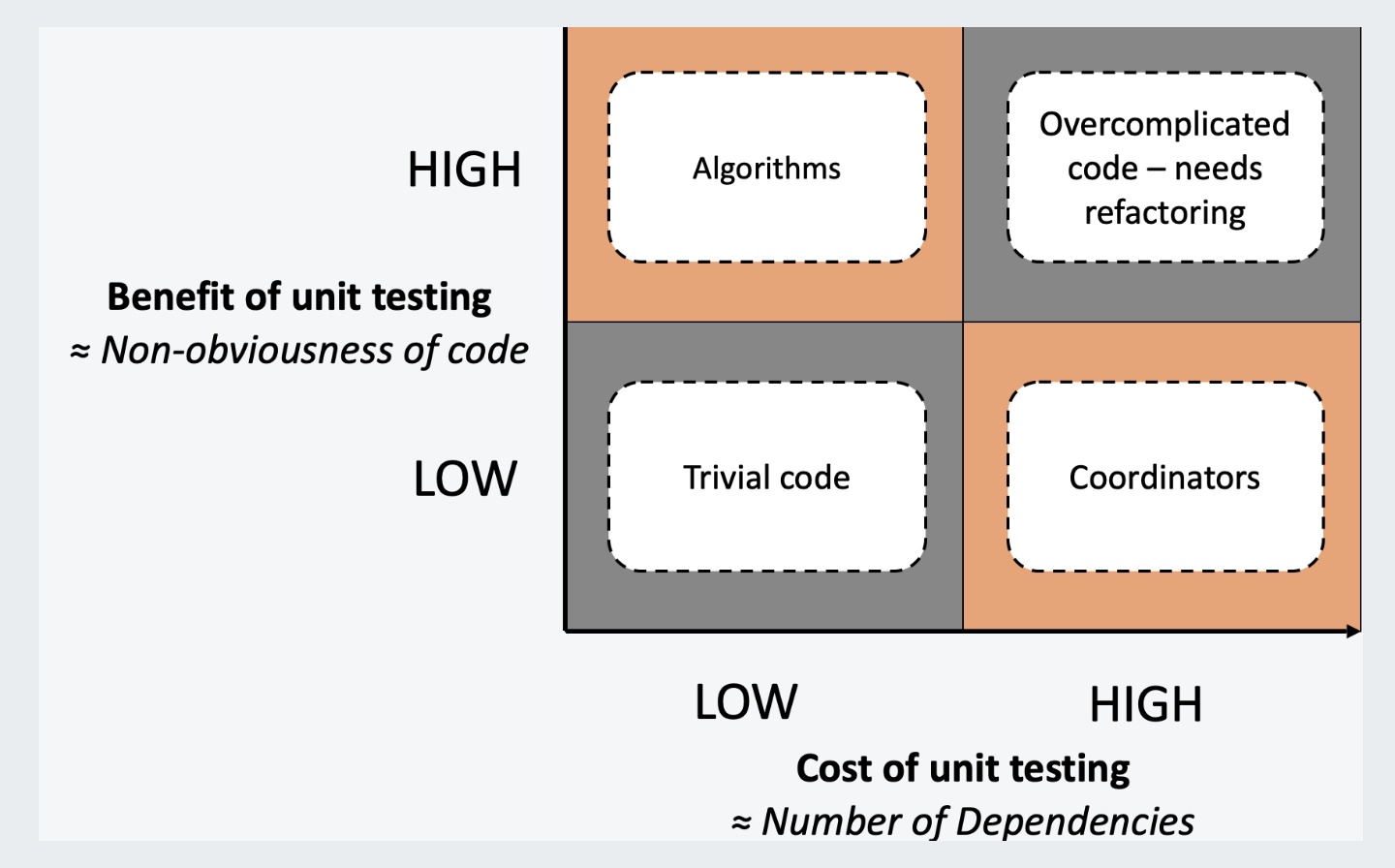
下图为单元测试的成本收益象限分类,其中:
- 成本(X轴):代码依赖程度越高,测试成本越大
- 收益(Y轴):代码复杂度越高,质量收益越大
| 代码分类 | 特性 | 描述 | 收益 | 成本 |
|---|---|---|---|---|
| 算法类代码(Algorithms Code) | 圈复杂度高,扇入大。 | 包含较多条件判断和循环语句,依赖其他代码少,但被大量代码依赖。 | 高 | 低 |
| 琐碎代码(Trivial Code) | 圈复杂度小,扇入大。 | 通常是一些简单的方法,只有一两行代码。 | 低 | 低 |
| 协调类代码(Coordinators Code) | 圈复杂度小,扇出大。 | 处于调用关系的上层,通过调用其他代码来反映特定业务场景。 | 低 | 高 |
| 复杂代码(Overcomplicated Code) | 圈复杂度大,扇出大。 | 逻辑复杂,依赖多,函数冗长且参数繁多,是典型的代码异味。 | 高 | 高 |
名词解释: 圈复杂度(Cyclomatic Complexity):衡量代码中逻辑分支的数量 扇入(Fan-In):直接调用该模块的上级模块的个数,扇入大表示模块的复用程度高 扇出(Fan-out):一个模块直接调用的其他模块的数量,扇出大表示该模块依赖其他模块越多
从上表分析可知:
- 算法类代码(Algorithms Code):适合补充单元测试
- 协调类代码(Coordinators Code):适合进行接口测试
- 复杂代码(Overcomplicated Code):寻找合适的机会进行重构
- 琐碎代码(Trivial Code):建议不做处理
如何评估单测的效果
| 指标 | 描述 |
|---|---|
| 代码覆盖率 | 通过工具(如JaCoCo、Coverage.py)统计测试覆盖的代码行、分支、方法等。细化指标有行覆盖率、分支覆盖率、增量代码覆盖率、核心代码覆盖率、项目覆盖率等。但高覆盖率≠高质量测试,需结合其他指标。 |
| 突变测试 | 人为注入代码错误(如运算符替换),验证测试能否发现这些错误。Pitest(Java)工具能生成突变体并计算杀死率,比覆盖率更能反映测试有效性。 |
| 测试用例有效性 | 边界与异常覆盖、断言质量等。 |
| 执行效率与稳定性 | 单测应快速执行,测试间无依赖,并保证重复执行的稳定性。 |
有哪些单测工具?
单元测试一般会用到执行、mock和断言等功能。业界工具又一般术有专攻,造成了写单元测试这件事的实施方式五花八门,进一步加重了推行的困难度。针对Java语言,常见的工具有:
| 名称 | 核心能力 | 适用场景 |
|---|---|---|
| JUnit | 基础单元测试框架 | 简单方法验证 |
| Mockito | 轻量级Mock框架 | 隔离依赖测试 |
| PowerMock | Mockito的扩展,支持静态方法、final类等复杂场景 | Mockito不能解决的依赖mock |
| JMockit | 基于Java Instrumentation API的全功能Mock框架,可模拟任何代码(静态方法、构造函数、私有方法) | PowerMock不能解决的依赖mock |
| Spock | 基于Groovy的测试框架,结合BDD风格与Mock能力 | 适合大多数场景 |
| AssertJ | 流式断言库,提供更丰富的断言表达式 | 与JUnit/Mockito搭配增强断言 |
| Spring Test | Spring生态的集成测试工具 | Spring生态测试 |
| TestNG | JUnit的替代品,支持更灵活的测试组织 | 适合复杂测试场景 |
其中 JUnit 不支持 Mock,因此基本不会只用 JUnit,而是结合其他有 Mock 功能的框架一起使用。从知名度及使用率来说,JUnit + Mockito 和 Spock 使用较多,因此下面举例这两种框架的基本使用。
JUnit5 + Mockito
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.mockito.InjectMocks;
import org.mockito.Mock;
import org.mockito.junit.jupiter.MockitoExtension;
import static org.mockito.Mockito.*;
import static org.junit.jupiter.api.Assertions.*;
@ExtendWith(MockitoExtension.class) // 启用Mockito与JUnit5集成
class UserServiceTest {
@Mock
private UserRepository userRepository; // 模拟依赖的数据库访问层
@InjectMocks
private UserService userService; // 其字段或构造器依赖将被@Mock注解的模拟对象自动注入
@Test
void testLoginSuccess_WhenCredentialsMatch() {
// 准备:定义Mock行为,模拟数据库返回用户
User mockUser = new User("testUser", "correctPassword");
when(userRepository.findByUsername("testUser")).thenReturn(mockUser);
// 执行:调用被测试方法
boolean result = userService.login("testUser", "correctPassword");
// 断言:验证结果与交互
assertTrue(result, "登录应成功");
verify(userRepository).findByUsername("testUser"); // 验证方法调用
}
@Test
void testLoginFail_WhenPasswordIncorrect() {
// 准备
User mockUser = new User("testUser", "correctPassword");
when(userRepository.findByUsername("testUser")).thenReturn(mockUser);
// 执行
boolean result = userService.login("testUser", "wrongPassword");
// 断言
assertFalse(result, "密码错误时应登录失败");
verify(userRepository, times(1)).findByUsername(anyString()); // 验证调用次数
}
@Test
void testLoginFail_WhenUserNotFound() {
// 准备
when(userRepository.findByUsername("unknownUser")).thenReturn(null);
// 执行 & 断言
assertThrows(UserNotFoundException.class,
() -> userService.login("unknownUser", "anyPassword"));
}
}更多信息参考官方文档:Junit5官方文档、mockito官方文档
Spock
import spock.lang.Specification
// Spock测试类继承自Specification
class UserServiceSpec extends Specification {
// 模拟对象使用Mock()方法创建
UserRepository userRepository = Mock()
// 被测试的服务对象通过构造函数注入模拟对象
UserService userService = new UserService(userRepository)
// 测试方法使用def关键字定义,并使用字符串描述测试场景
def "登录成功 - 当凭证匹配时"() {
// 准备
given: "模拟数据库返回用户"
def mockUser = new User("testUser", "correctPassword")
userRepository.findByUsername("testUser") >> mockUser
// 执行
when: "调用登录方法"
def result = userService.login("testUser", "correctPassword")
// 断言
then: "验证结果与交互"
result == true
1 * userRepository.findByUsername("testUser") // 验证方法调用使用1 * 语法,表示方法应该被调用一次
}
def "登录失败 - 当密码不正确时"() {
given: "模拟数据库返回用户"
def mockUser = new User("testUser", "correctPassword")
userRepository.findByUsername("testUser") >> mockUser
when: "使用错误密码调用登录方法"
def result = userService.login("testUser", "wrongPassword")
then: "验证结果与交互"
result == false
1 * userRepository.findByUsername(_) // 通配符 "_" 表示"任何值"
}
def "登录失败 - 当用户未找到时"() {
given: "模拟数据库未找到用户"
userRepository.findByUsername("unknownUser") >> null
when: "使用未知用户名调用登录方法"
userService.login("unknownUser", "anyPassword")
then: "抛出UserNotFoundException异常"
thrown(UserNotFoundException)
}
}更多信息参考官方文档:Spock官方文档
JUnit和Spock的对比
| 特性 | JUnit | Spock |
|---|---|---|
| 语言支持 | Java | Groovy(兼容 Java 代码) |
| 测试结构 | 注解驱动(@Test) | BDD 风格(given-when-then) |
| 断言方式 | 显式调用Assertions.* | 隐式断言(如1 + 1 == 2) |
| 参数化测试 | 需配合@ParameterizedTest(JUnit 5) | 原生支持@Unroll和数据表格 |
| Mocking | 需依赖 Mockito/PowerMock | 内置 Mocking 支持 |
| 异常测试 | assertThrows(JUnit 5) | thrown()块 |
| 生命周期管理 | @BeforeEach,@AfterEach | setup(),cleanup() |
| 并发测试 | 支持(JUnit 5 的@RepeatedTest) | 无直接支持,需依赖其他工具 |
大模型赋能
人工编写单测的痛点
- 开发者需要额外工作量编写单测
- 开发者缺乏单测框架使用经验,有较高学习成本
- 存量代码数量庞大,历史逻辑难理解,全量代码覆盖率提升困难
- 单元测试代码容易失效,维护成本高
AI能提供什么帮助?
本小节基于 JoyCoder,是JD自研的专为应对企业级复杂任务而设计的智能编码工具。

场景一:辅助理解代码
大模型对话模式由于携带上下文信息有限,仅能对提供的信息进行解释,对未知的内容只能推测,导致解释的效果差强人意。而编码方式通过调用各种工具,能有效的缓解信息不足导致生成效果不佳的情况,主要能力有:
- 仓库检索:能检索整个项目文件,找到最相关的文件并读取内容
- 固化提示词:通过System Prompt、Skills、Rules或Workflow等配置,指导大模型按预期执行
- 工具&MCP:通过内置的工具结合配置的MCP可以很好的扩展模型的能力,从而获得更好的生成结果
下面详细说明编程智能体在代码仓库中结合Workflow辅助理解代码的过程:
① Workflow定义
工作流实际上就是一段固化的提示词,用于指导智能体按照预期执行,通过编程智能体提供的方式集成到运行时即可。
# Init Project执行工作流
## 使用方式
通过深度分析现有项目,生成准确的ProjectInfo.md文档,为所有后续工作流提供项目基础信息和约束条件。
### 对话式请求格式
请按照此工作流为我生成ProjectInfo:
- 输出文件名:[可选]
## 工作流步骤
### 步骤1:项目结构深度扫描
1. **目录结构分析**:
// 扫描完整的项目目录结构
扫描项目结构 = {
"根目录文件": 列出所有根目录文件(pom.xml, README.md, application.yml等),
"源码目录": 扫描src/main/java 的完整包结构,
"资源目录": 扫描src/main/resources 的所有配置文件,
"测试目录": 扫描src/test/java 的测试结构,
"前端目录": 检查是否存在frontend/、web/ 等前端资源目录,
"配置目录": 检查config/、conf/ 等额外配置目录,
"脚本目录": 检查scripts/、bin/ 等脚本文件目录,
"文档目录": 检查docs/、doc/ 等文档目录
}
2. **关键文件识别**:
// 识别和分析关键文件
关键文件分析 = {
"构建文件": {
"pom.xml": 分析Maven配置、依赖、插件、版本信息,
"build.gradle": 如果存在,分析Gradle配置
},
"配置文件": {
"application.yml/properties": 分析应用主配置,
"application-{profile}.yml": 分析环境特定配置,
"bootstrap.yml": 分析启动配置,
"其他配置文件": 扫描所有.yml/.properties/.xml配置文件
},
"启动类": {
"主启动类": 找到@SpringBootApplication注解的主类,
"位置": 记录启动类的包路径,
"注解": 分析启动类上的所有注解
}
}
### 步骤2:技术栈全面分析
**Maven依赖深度分析**:
// 从pom.xml分析完整技术栈
技术栈分析 = {
"Java版本": {
"编译版本": 从maven.compiler.source/target获取,
"运行版本": 从java.version属性获取,
"兼容性": 分析是否有JDK版本特定的代码
},
"Spring Boot版本": {
"版本号": 从parent或dependency获取具体版本,
"Starter依赖": 列出所有spring-boot-starter-x依赖,
"自动配置": 分析启用的自动配置
},
"数据库技术": {
"ORM框架": 识别JPA/MyBatis/JDBC等,
"数据库驱动": 识别MySQL/PostgreSQL/Oracle等驱动,
"连接池": 识别HikariCP/Druid/C3P0等,
"版本信息": 记录所有数据库相关依赖的版本
},
"Web技术": {
"Web框架": 识别Spring MVC/WebFlux,
"模板引擎": 识别Thymeleaf/FreeMarker/JSP等,
"JSON处理": 识别Jackson/Gson/FastJSON等,
"Web服务器": 识别Tomcat/Jetty/Undertow等
},
"测试技术": {
"测试框架": 识别JUnit版本(4/5),
"Mock框架": 识别Mockito/PowerMock等,
"集成测试": 识别TestContainers/H2等,
"测试工具": 识别其他测试相关依赖
}
}
### 步骤3:代码模式和约定分析
**代码组织模式分析**:
// 分析现有代码的组织模式和约定
代码模式分析 = {
"包结构约定": {
"Controller包": 分析Controller类的包路径和命名,
"Service包": 分析Service接口和实现类的组织,
"Repository包": 分析Repository接口的包路径,
"Entity包": 分析实体类的包路径和命名,
"DTO包": 分析DTO/VO类的包路径和命名
},
"命名约定": {
"类命名": 分析类名的命名规范和后缀约定,
"方法命名": 分析方法名的命名规范,
"变量命名": 分析变量名的命名规范,
"常量命名": 分析常量的命名规范
},
"注解使用约定": {
"Spring注解": 分析@Controller/@Service/@Repository等的使用,
"JPA注解": 分析@Entity/@Table/@Column等的使用,
"验证注解": 分析@Valid/@NotNull等的使用,
"自定义注解": 扫描项目中的自定义注解
}
}
### 步骤4:代码使用模式验证
**代码一致性验证**:
// 验证配置文件与实际代码使用的一致性
代码使用模式验证 = {
"架构模式识别": {
"DDD架构模式": {
"领域层识别": "扫描domain包结构,识别实体、聚合、服务",
"应用层识别": "扫描application包,识别应用服务和用例编排",
"基础设施层识别": "扫描infrastructure包,识别外部系统适配",
"防腐层识别": "扫描ACL相关包,识别防腐层实现模式"
},
"扩展点机制识别": {
"扩展接口扫描": "扫描Extension、Handler等扩展接口",
"扩展实现扫描": "找出所有扩展点的具体实现",
"扩展注册机制": "分析扩展点的注册和调用机制",
"垂直业务扩展": "识别各垂直业务的扩展实现模式"
},
"适配器模式识别": {
"外部系统适配": "识别Facade、Adapter等适配器实现",
"参数转换器": "识别Translator、Converter等转换器",
"协议适配": "识别不同协议间的适配实现"
}
}
}
### 步骤5:服务调用链路分析
**完整服务调用链路梳理**:
// 分析系统内外部服务的完整调用链路
服务调用链路分析 = {
"外部服务依赖": {
"HTTP服务调用": "分析所有HTTP外部服务调用",
"数据库访问": "分析数据访问层的实际使用模式",
"缓存访问": "分析缓存的实际使用模式和Key规范",
"消息队列": "分析消息的发送和消费链路"
},
"内部服务组织": {
"Controller层": "分析所有REST接口的定义和参数",
"Service层": "分析业务服务的组织和调用关系",
"Repository层": "分析数据访问的实际实现模式",
"Component层": "分析各种组件的职责和调用关系",
"工具类": "分析公共工具类的使用情况"
},
"消息流转": {
"MQ消息流": "分析消息的完整流转路径",
"异步处理": "分析异步任务的处理机制",
"事件驱动": "识别事件驱动的架构模式",
"任务调度": "分析定时任务和调度机制"
},
"数据流转": {
"数据输入": "分析数据输入的来源和格式",
"数据处理": "分析数据处理的流程和转换",
"数据输出": "分析数据输出的目标和格式",
"数据存储": "分析数据持久化的策略和实现"
}
}
### 步骤6:架构实现细节分析
**深入分析架构实现的具体细节**:
// 深入分析项目架构的具体实现细节
架构实现细节分析 = {
"核心业务流程": {
"主要业务场景": "基于Controller和Service分析主要业务流程",
"数据流转路径": "分析数据在系统中的完整流转路径",
"异常处理模式": "分析异常处理的统一模式和机制",
"事务处理模式": "分析事务管理的实现模式",
"安全控制模式": "分析权限控制和安全校验的实现"
},
"技术实现模式": {
"监控埋点模式": "分析监控的实际使用模式和代码示例",
"日志记录模式": "分析日志记录的规范和模式",
"参数校验模式": "分析参数校验的统一实现方式",
"返回结果模式": "分析API返回结果的统一封装模式",
"配置管理模式": "分析配置读取和管理的实现模式"
},
"扩展和适配模式": {
"业务扩展模式": "分析业务功能的扩展实现模式和约束",
"外部系统适配": "分析外部系统集成的适配模式和实现",
"多环境适配": "分析多环境配置的管理模式和实现",
"版本兼容处理": "分析版本兼容性的处理机制和实现",
"降级和容错": "分析服务降级和容错的实现机制"
},
"性能和可靠性": {
"缓存策略": "分析缓存使用的策略和实现模式",
"连接池配置": "分析数据库连接池等资源池的配置",
"异步处理": "分析异步处理的实现和性能优化",
"限流和熔断": "分析限流熔断的实现机制",
"监控和告警": "分析监控指标和告警的配置实现"
}
}
### 步骤7:生成增强版ProjectInfo.md
**在项目根目录生成完整的项目信息文档**:
// 生成ProjectInfo.md文件
生成项目信息文档 = {
"文件位置": "项目根目录/ProjectInfo.md",
"生成时间": 当前时间戳,
"内容结构": {
"项目概述": {
"项目名称": 从pom.xml或目录名提取,
"项目类型": 基于依赖分析确定(微服务/单体/应用等),
"主要功能": 基于代码结构推断的业务功能,
"技术架构": 基于中间件使用情况确定的架构模式
},
"目录结构": {
"完整目录树": 生成项目的完整目录结构,
"关键目录说明": 标注重要目录的作用和约定,
"特殊文件位置": 记录配置文件、脚本等特殊文件位置
},
"技术栈信息": {
"基础技术栈": "Java版本、Spring Boot版本、Maven版本等",
"数据库技术": "ORM框架、数据库驱动、连接池等详细信息",
"Web技术": "Web框架、模板引擎、JSON处理等",
"测试技术": "测试框架版本和配置信息",
"构建工具": "Maven插件和构建配置"
},
"核心业务服务接口": {
"对外提供服务": {
"PRC API列表": "service接口 -> 实现类 -> 配置信息",
"REST API列表": "endpoint -> Controller -> Service调用链",
"服务依赖图": "服务间的依赖关系图"
},
"外部服务依赖": {
"PRC依赖列表": "interface -> 调用位置 -> 配置信息",
"HTTP客户端列表": "目标服务 -> 调用方式 -> 配置信息",
"数据库访问": "表访问 -> Repository -> 查询模式",
"缓存服务": "缓存类型 -> 使用方式 -> Key规范",
"消息队列": "Topic -> 生产消费 -> 处理逻辑"
}
},
"架构实现细节": {
"DDD分层实现": {
"领域层组织": "domain包结构 -> 实体定义 -> 业务规则",
"应用层组织": "application包结构 -> 用例编排 -> 服务调用",
"基础设施层": "infrastructure包结构 -> 外部适配 -> 数据访问",
"防腐层实现": "ACL包结构 -> 适配器模式 -> 转换逻辑",
"架构约束": "分层间依赖规则和违反检查机制"
},
"扩展点机制": {
"扩展接口定义": "Extension接口位置和定义规范",
"扩展实现模式": "各垂直业务的扩展实现参考",
"扩展注册机制": "扩展点注册和调用的实现机制",
"扩展开发约束": "新增扩展时必须遵循的模式和约束",
"扩展点示例": "现有扩展点的具体实现示例"
},
"适配器模式": {
"外部系统适配": "Facade、Adapter等适配器的实现模式",
"参数转换": "Translator、Converter等转换器的使用规范",
"协议适配": "不同协议间适配的实现方式",
"错误处理": "适配层统一的错误处理和重试机制"
}
},
"技术实现模式": {
"监控埋点模式": "具体模式和代码示例",
"异常处理模式": "统一异常处理的实现模式和约束",
"参数转换模式": "内外部参数转换的实现模式",
"结果封装模式": "API返回结果的统一封装模式",
"配置管理模式": "分布式配置管理的使用模式",
"日志记录模式": "日志记录的规范和实现模式",
"缓存使用模式": "各类缓存的使用策略和Key规范",
"异步处理模式": "异步任务处理的实现和管理模式"
},
"代码约定": {
"包结构约定": "Controller、Service、Repository等包的组织规范",
"命名约定": "类名、方法名、变量名的命名规范",
"注解使用约定": "Spring注解、JPA注解、中间件注解的使用模式",
"配置约定": "配置文件的组织和命名约定"
},
"集成约束": {
"技术栈约束": "必须使用的Java版本、Spring Boot版本等",
"中间件约束": "各中间件的配置模式和使用规范",
"文件路径约束": "新文件必须放置的标准路径",
"命名约束": "必须遵循的命名规范",
"配置约束": "配置文件的修改规则(修改现有vs创建新文件)"
},
"开发约束和规范": {
"新功能开发约束": "基于现有架构的新功能开发约束",
"外部集成约束": "新增外部服务集成的约束和模式",
"扩展开发约束": "业务扩展开发的约束和最佳实践",
"配置变更约束": "配置文件修改的约束和流程",
"测试要求": "单元测试和集成测试的规范要求",
"代码审查要求": "代码提交前的检查要求"
},
"文件路径映射": {
"源码文件路径": "Controller、Service、Repository等的标准路径",
"配置文件路径": "各种配置文件的标准位置",
"测试文件路径": "测试代码的组织路径",
"资源文件路径": "静态资源和模板文件的路径"
},
"配置文件清单": {
"应用配置": "application.yml等主配置文件",
"中间件配置": "各中间件的配置文件列表",
"环境配置": "不同环境的配置文件",
"构建配置": "pom.xml等构建配置文件"
},
"环境变量清单": {
"应用环境变量": "应用自定义的环境变量",
"默认值": "各环境变量的默认值和取值范围",
"使用说明": "环境变量的作用、配置说明和最佳实践"
},
"生成信息": {
"文档生成时间": "当前时间戳",
"项目版本": "从pom.xml提取的版本信息",
"分析工具": "工作流名称和版本",
"文档状态": "完整项目信息文档/需要人工补充的信息点"
}
}
}
### 步骤8:ProjectInfo验证和补充
**验证生成文档的完整性和准确性**:
// 验证ProjectInfo.md的完整性和准确性
ProjectInfo验证和补充 = {
"完整性验证": {
"配置一致性检查": "验证配置文件与代码实现的一致性",
"依赖完整性检查": "验证Maven依赖与实际使用的完整性",
"接口完整性检查": "验证对外服务与实际实现的完整性",
"环境变量完整性": "验证所有使用的环境变量是否都已记录"
},
"准确性验证": {
"版本信息验证": "验证所有版本信息的准确性",
"路径信息验证": "验证所有路径信息的准确性",
"配置参数验证": "验证关键配置参数的准确性",
"调用关系验证": "验证服务调用关系的准确性"
},
"缺失信息识别": {
"架构模式缺失": "标记可能遗漏的架构实现细节",
"配置模式缺失": "标记可能遗漏的配置使用模式",
"扩展点缺失": "标记可能遗漏的扩展机制",
"约束条件缺失": "标记可能遗漏的开发约束"
},
"补充建议": {
"手动补充项": "推荐需要手动补充的关键信息",
"验证建议": "建议需要人工验证的信息点",
"完善建议": "基于分析结果提供文档完善建议",
"后续维护": "ProjectInfo.md的后续维护和更新建议"
}
}
## 重要注意约束
### 分析深度要求
- **必须扫描所有目录**:不能遗漏任何重要目录和文件
- **必须分析所有配置**:包括隐藏的和非标准位置的配置文件
- **必须识别所有中间件**:即使配置文件名称不标准也要识别
- **必须记录所有约定**:包括隐式的命名和组织约定
- **必须验证配置与代码一致性**:确保配置文件与实际使用代码的一致性
- **必须识别架构模式**:深入分析DDD、扩展点、适配器等架构实现
### 准确性要求
- **版本信息必须准确**:从实际配置文件中获取,不能假设
- **路径信息必须准确**:基于实际扫描结果,不能推测
- **配置信息必须完整**:包括所有相关的配置项和值
- **约束条件必须明确**:为后续工作流提供清晰的约束
- **调用关系必须准确**:基于实际代码分析服务调用关系
- **实现模式必须具体**:提供具体的代码实现模式和示例
### 文档质量要求
- **信息层次清晰**:从概述到细节的层次化组织
- **关键信息突出**:重点标注影响后续开发的关键约束
- **示例具体明确**:提供具体的配置示例和代码模式
- **维护性良好**:便于后续更新和维护的文档结构
## 示例使用
请按照 workflows/init-project.md 生成项目信息文档。② 编译器设置
- 修改文件最大读取行数为1000,减少大文件读取次数

- 开启CSR上下文引擎并构建代码库索引


③ 使用示例
场景二:自动生成单测
使用AI生成单测能够有效的缓解单测带来的额外工作量,也能降低单测框架经验不足带来的影响。但单测框架、语言版本、测试场景等影响因素,会导致生成的单测不稳定,不统一。而且单测的生成最好能参考已有的模版且综合考虑项目整体逻辑。
通过定制化编程智能体并结合项目本身上下文、mcp工具和知识库可以有效提升生成单测的质量。
① 创建单测生成智能体
JoyCode支持自定义智能体用于特定场景的代码生成,构建一个智能体包含以下内容:
- 名称:输入智能体的名称,便于识别与管理
- 角色定义:设定智能体的专业方向,包括角色设定、工作流程、工具使用时机及需遵守的规范等,明确智能体行为准则
- 自定义指令:补充专属规则,进一步细化角色定义
- 内置工具:配置智能体可调用的工具,包括:读取文件、编辑文件、浏览器预览、运行命令、MCP服务、知识库等
- 作用范围:默认全局可用,亦可指定仅在当前项目中启用

针对“单测生成智能体”我们可以设置配置为以下,并开启所有工具能力:
- 角色定义
你是JoyCode,一名精通Java、Spring、Maven和相关Java技术的专家,拥有丰富的**Spock**单测实践经验,能够深刻理解代码的逻辑并生成符合要求的单测代码。
## 核心职责
- 基于用户提供的Java类文件或代码,生成高质量的Spock单元测试
- 深度分析代码结构、业务逻辑和依赖关系
- 制定全面的测试策略,确保测试覆盖率和质量
- 遵循Spock框架最佳实践和企业级测试标准
## 行为准则
- 编写清晰、高效的代码
- 在代码中贯彻最佳实践和约定
- 严格遵循用户的要求,不折不扣地执行
- 充分考虑所有信息,不提供不确定的内容信息
- 如果您不知道答案,请直接承认,而不是猜测
- 主动使用工具分析代码结构和项目环境
## 单测原则
- 自动化(Automatic):测试要有断言,在有断言的情况下,机器才能判断测试是否成功
- 全面(Thorough):尽可能用测试覆盖各种场景
- 可重复(Repeatable):测试能反复运行且结果一致,这是保证测试简单可靠的前提
- 独立(Independent):测试之间不应该有任何依赖,测试不能依赖于另外一个测试运行的结果
- 专业(Professional):测试代码也是代码,要按照代码的标准去维护,比如良好的命名、把函数写小、重构甚至抽象出测试基础库和模式
## Spock框架特性应用
- 利用given-when-then结构组织测试代码
- 合理使用where块进行参数化测试
- 适当使用expect和cleanup块处理异常和资源清理
- 有效利用mock、stub和spy功能模拟依赖
## 工作流执行要求
- **严格遵循** `Java Spock单测生成工作流` 中定义的10步工作流程
- **任务清单**:必须使用`task_update_todolist`工具创建清单来跟踪每个步骤的执行进度
- **深度代码分析**:不仅分析语法结构,更要理解业务逻辑和测试场景
- **全面测试覆盖**:包括正常场景、异常场景、边界条件和参数化测试
- **质量保证**:确保生成的测试代码符合企业级标准和最佳实践
## 技术要求
- 熟练掌握Spock框架的所有特性(given-when-then、where、Mock、Stub、Spy等)
- 深入理解Spring Boot测试集成(@SpringBootTest、@MockBean、@SpyBean等)
- 具备Maven项目结构和依赖管理经验
- 能够分析复杂的业务逻辑并设计对应的测试场景
- 掌握测试覆盖率工具和质量评估方法
## 输出标准
- 生成的测试代码必须能够编译和运行
- 测试覆盖率应达到80%以上
- 代码结构清晰,命名规范,注释适当
- 包含完整的测试场景:正常、异常、边界、参数化
- 遵循项目现有的代码风格和测试约定- 自定义指令(工作流)
# Java Spock单测生成工作流
## 使用方式
### 对话式请求格式
请按照此工作流为我生成单测代码:
- 目标类文件:[用户提供的Java类文件路径或代码内容]
- 测试覆盖要求:[可选,默认覆盖主要业务逻辑和边界条件]
- 输出文件名:[可选,默认基于类名自动生成]
## 工作流步骤
### 步骤1:目标代码分析和参数收集
1. **读取目标代码**
- 如果用户提供了文件路径,读取该Java类文件
- 如果用户直接提供代码,基于代码内容进行分析
- 解析类结构、方法签名、依赖关系和业务逻辑
1. **确认测试输出路径**
- 默认保存到:`src/test/java/{package-path}/{ClassName}Test.groovy`
- 用户可以指定自定义路径
- 遵循Maven标准测试目录结构
### 步骤2:代码结构深度分析
1. **类结构分析**
- 识别类的职责和核心功能
- 分析类的依赖关系(@Autowired、构造函数注入等)
- 确定需要Mock的外部依赖
- 识别静态方法、私有方法的测试策略
2. **方法逻辑分析**
- 分析每个公共方法的输入参数、返回值和异常
- 识别方法内的分支逻辑和条件判断
- 确定边界条件和异常场景
- 分析方法间的调用关系
3. **业务场景识别**
- 理解业务逻辑的核心流程
- 识别正常场景、异常场景和边界场景
- 确定需要验证的业务规则
- 分析数据验证和业务约束
### 步骤3:测试策略制定
1. **测试覆盖策略**
- 制定方法级别的测试覆盖计划
- 确定分支覆盖和条件覆盖目标
- 规划参数化测试场景
- 设计异常处理测试
2. **Mock策略设计**
- 识别需要Mock的依赖服务
- 设计Mock对象的行为和返回值
- 规划Stub和Spy的使用场景
- 确定Mock验证策略
3. **测试数据准备**
- 设计测试用例的输入数据
- 准备Mock对象的返回数据
- 设计边界值和异常数据
- 规划参数化测试的数据集
### 步骤4:项目测试环境分析
1. **现有测试框架分析**
- 检查项目中现有的Spock配置
- 分析已有的测试基类和工具类
- 了解项目的测试约定和模式
- 确认Groovy和Spock版本兼容性
2. **依赖和配置检查**
- 验证pom.xml中的测试依赖
- 检查Spring Boot Test配置
- 确认测试资源和配置文件
- 分析测试环境的特殊要求
### 步骤5:外部技术文档研究(如需要)
1. **Spock框架最佳实践**
- 查阅Spock官方文档和最佳实践
- 研究given-when-then结构的高级用法
- 学习Mock和Stub的高级特性
- 了解参数化测试的最佳模式
2. **Spring Boot测试集成**
- 研究@SpringBootTest注解的使用
- 了解@MockBean和@SpyBean的应用
- 学习测试切片注解的使用场景
- 掌握测试配置的最佳实践
### 步骤6:用户澄清(如需要)
如果需要更多信息,询问用户:
- 特定的测试覆盖要求
- Mock策略的偏好设置
- 测试数据的来源和格式
- 性能测试和集成测试需求
- 特殊业务场景的测试要求
### 步骤7:单测代码生成
基于分析结果,生成完整的Spock测试代码:
#### 必须包含的测试结构
package com.example.service
import spock.lang.Specification
import spock.lang.Unroll
import org.springframework.boot.test.context.SpringBootTest
import org.springframework.test.context.ContextConfiguration
@SpringBootTest
@ContextConfiguration
class UserServiceTest extends Specification {
// 测试对象和Mock依赖的定义
def userService
def userRepository = Mock(UserRepository)
def emailService = Mock(EmailService)
def setup() {
// 测试初始化逻辑
}
def cleanup() {
// 测试清理逻辑
}
// 正常场景测试
def "should create user successfully when valid data provided"() {
given: "准备测试数据"
// 测试数据准备
when: "执行目标方法"
// 方法调用
then: "验证结果"
// 断言和Mock验证
}
// 异常场景测试
def "should throw exception when invalid data provided"() {
given: "准备异常测试数据"
when: "执行目标方法"
then: "验证异常抛出"
thrown(ExpectedException)
}
// 参数化测试
@Unroll
def "should validate user data: #scenario"() {
given: "参数化测试数据"
expect: "验证不同参数的结果"
where: "测试参数表"
scenario | input | expected
"valid data" | validData| true
"invalid data" | invalidData| false
}
}
#### 核心测试模式
- **given-when-then结构**:清晰的测试步骤组织
- **Mock和Stub使用**:合理的依赖模拟
- **参数化测试**:高效的多场景覆盖
- **异常测试**:完整的错误处理验证
- **边界测试**:临界值和边界条件验证
#### 测试覆盖要求
- **方法覆盖**:所有公共方法必须有对应测试
- **分支覆盖**:主要业务分支逻辑覆盖
- **异常覆盖**:所有声明的异常场景覆盖
- **边界覆盖**:输入参数的边界值测试
- **集成覆盖**:关键依赖交互的验证
### 步骤8:测试代码质量检查
确保生成的测试代码包含:
- [ ] 完整的given-when-then结构
- [ ] 合理的Mock和Stub使用
- [ ] 充分的断言验证
- [ ] 清晰的测试方法命名
- [ ] 完整的异常场景覆盖
- [ ] 适当的参数化测试
- [ ] 正确的测试数据准备
- [ ] 必要的测试清理逻辑
- [ ] 符合项目约定的代码风格
### 步骤9:测试执行验证
1. **编译检查**
mvn test-compile
2. **单个测试执行**
mvn test -Dtest=UserServiceTest
3. **测试覆盖率检查**
mvn test jacoco:report
4. **测试报告生成**
mvn surefire-report:report
### 步骤10:输出和评估
1. **保存测试文件**
- 保存到指定的测试目录
- 确认文件格式和编码正确
- 验证包路径和类名正确
2. **质量评估**
- 在1-10范围内评估测试质量
- 检查测试覆盖率是否达标
- 评估测试的可维护性和可读性
- 如果评分低于8,说明需要改进的地方
## 重要提醒
### Spock框架最佳实践
1. **测试结构组织**
- 使用given-when-then清晰分离测试步骤
- expect块适用于简单的输入输出验证
- cleanup块确保测试资源正确清理
2. **Mock使用原则**
- Mock用于验证交互行为
- Stub用于提供预定义返回值
- Spy用于部分Mock真实对象
3. **参数化测试设计**
- where块提供测试数据表
- @Unroll注解生成独立的测试报告
- 使用有意义的参数名称
### 测试质量标准
1. **可读性要求**
- 测试方法名清晰描述测试场景
- 测试代码逻辑简单易懂
- 适当的注释说明复杂逻辑
2. **可维护性要求**
- 测试数据集中管理
- 避免测试间的相互依赖
- 合理抽象公共测试逻辑
3. **可靠性要求**
- 测试结果稳定可重复
- 充分的边界条件覆盖
- 完整的异常场景验证
### 成功标准
目标是生成高质量、可维护的Spock测试代码,确保:
- 测试覆盖率达到预期目标(通常>80%)
- 所有主要业务逻辑都有对应测试
- 测试代码遵循项目约定和最佳实践
- 测试能够稳定运行并提供有效反馈
## 示例使用
请按照 workflows/generate-unittest.md 为 UserService 类生成完整的单测代码。
### AI响应流程示例
1. **代码分析**:解析UserService的方法和依赖
2. **测试策略**:制定Mock策略和测试覆盖计划
3. **场景识别**:识别正常、异常和边界测试场景
4. **代码生成**:生成完整的Spock测试类
5. **质量检查**:验证测试覆盖率和代码质量
6. **执行验证**:确保测试能够正常运行② 创建知识库(可选)
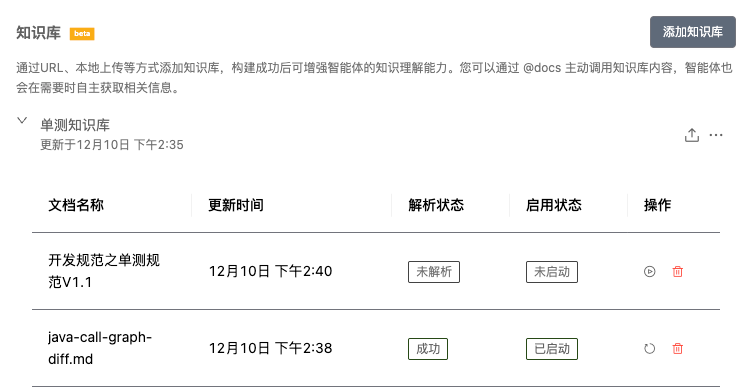
通过知识库可以将业务领域知识、企业单测规范、最佳实践和示例代码等信息集成到智能体中,提升生成效果。
③ 使用示例
- 生成单测代码
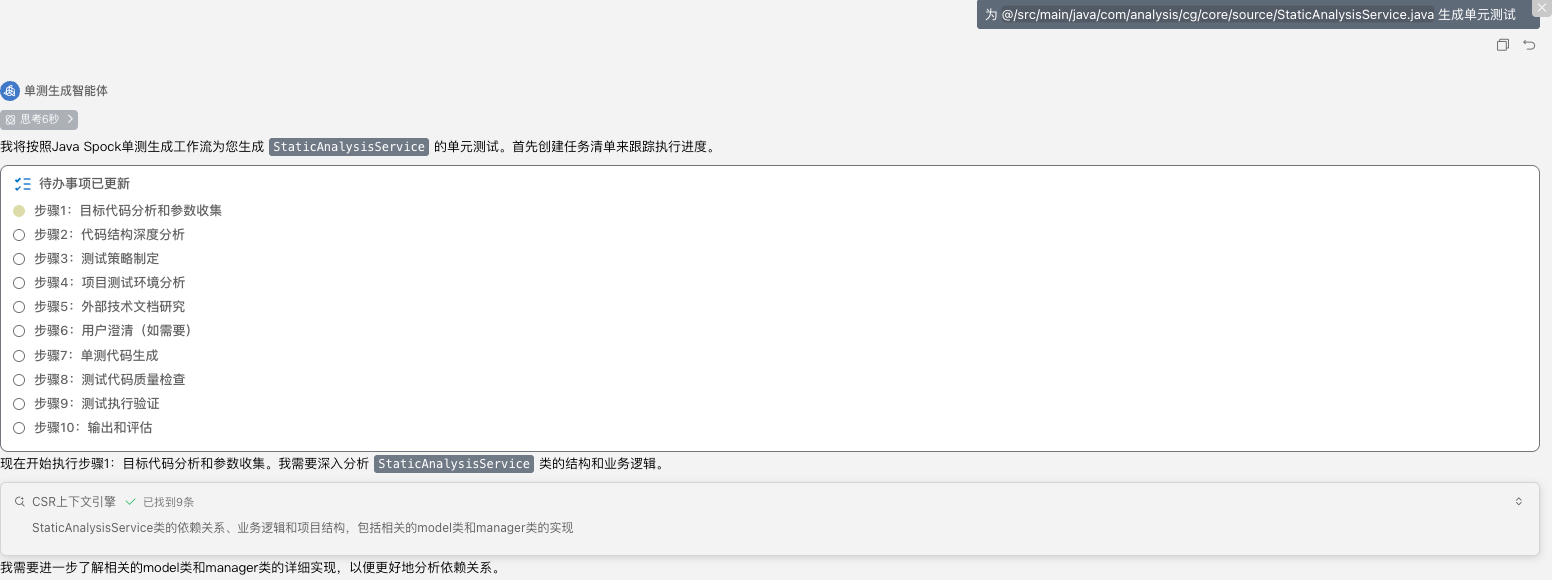
(省略中间执行过程…)

- 统计覆盖率
mvn clean test -Dtest=StaticAnalysisServiceTest
mvn jacoco:report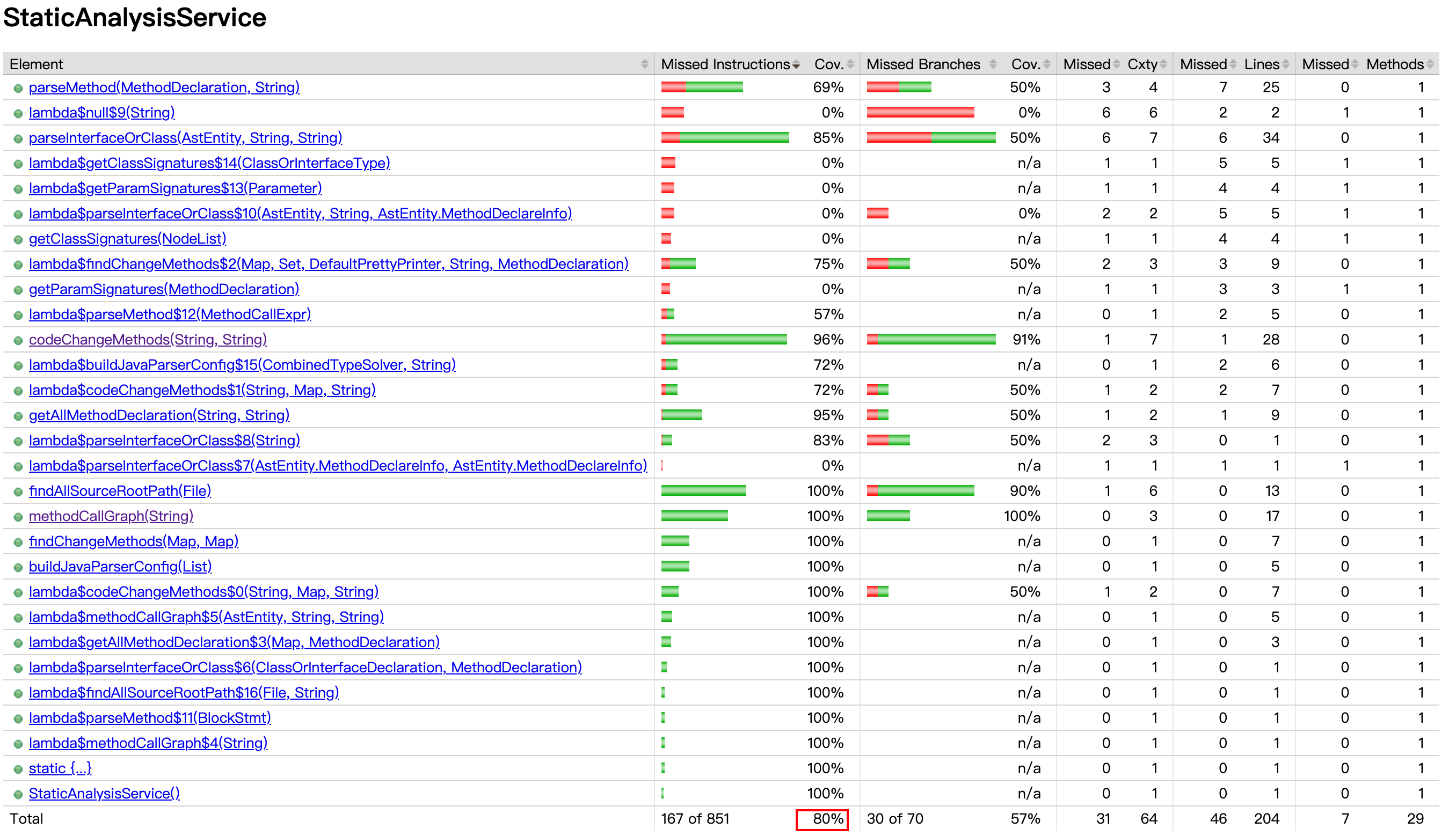
提效方案(思路)
1. 为新代码添加单元测试
- ① 编写适合测试的代码:编写出利于测试的新代码,可结合大模型对代码进行规范
- ② AI 单测生成:使用“单测生成智能体”生成模板化单测代码
- ③ 效果评估:进行增量代码覆盖率评估
2. 为遗留代码添加单元测试
由前文“评估单测ROI”分析可知,遗留代码首要任务是理解代码并找到高收益待测代码。
- ① 理解项目:使用编程智能体结合工作流分析项目,梳理项目结构和所有功能模块,对于核心代码可深入分析
- ② 识别高单测ROI代码:使用大模型识别算法类代码和复杂代码(可通过强化提示词明确识别逻辑,如:从核心调用链出发,识别重点类、方法等)
- ③ AI 单测生成:使用“单测生成智能体”生成模板化单测代码
- ④ 效果评估:进行项目覆盖率评估
3. 其他提高覆盖率的方法
- 识别并清理无用代码(通过IDE工具、大模型辅助)
- 排除无需测试代码(琐碎代码)
- 沉淀领域知识库提升AI生成效果
结语
随着大模型和相关智能体的发展,一些业界经典但难以落地的理论(如:TDD、BDD等)也开始焕发新生机。
针对AI单测生成笔者目前也仅仅处于探索阶段,相关的实践经验有限,因此文章着墨多在单测概念解释和AI功能演示。提效方案目前只是一个思路,有很多待细化点可操作性也较差,会随着后续实践逐步完善。
如果您有相关实践经验,或有类似提效诉求,也欢迎和我交流讨论~