1. 编译器概述
编译器:将用编程语言(源语言)编写的计算机代码翻译成另一种语言(目标语言)的计算机程序。
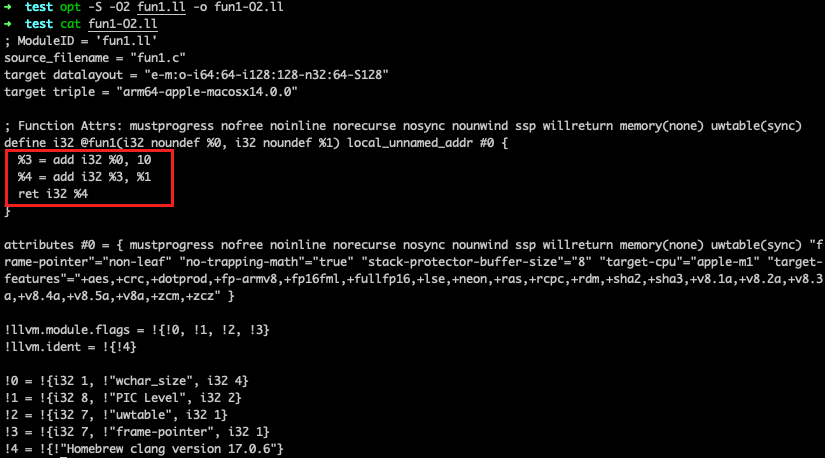
编译程序以高级程序源代码作为输入,以汇编语言或机器语言表示的目标程序作为输出。目标程序会在机器上运行,得到所需的结果。编译器可能执行以下操作:预处理、词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成。
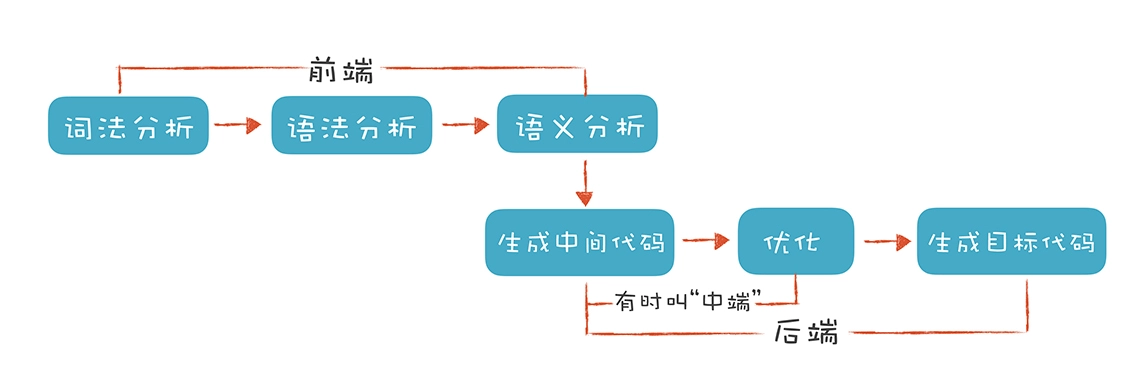
编译器前端和中端理论知识与代码可视化的实现最为相关,后端部分和目标机器代码、特定机器架构相关一般很少用到可视化中。
2. 中间代码优化
IR存在的意义是使得代码优化变得容易且可复用,不同的中间表达方式也是为了方便不同优化手段的执行。对代码做优化的方法有很多,如果把它们分类一下的话,可以按照下面两个维度:
- 按是否机器相关分类:
- 机器无关优化(Machine-Independent Optimization):这类优化不依赖于目标机器的具体硬件特性,主要关注于高级语言构造的改进和通用的算法改进。例如:常量折叠、死代码消除、循环不变代码外提等;
- 机器相关优化(Machine-Dependent Optimization):这类优化依赖于目标机器具体硬件特性,如寄存器的数量、指令集特点等。例如:寄存器分配、指令选择、指令级并行优化等。
- 按优化的范围分类:
- 本地优化(Local Optimization):关注于程序中小的片段,通常是一个基本块内的优化。这类优化不考虑跨基本块的控制流和数据流。例如:公共子表达式消除、死代码消除等;
- 全局优化(Global Optimization):考虑整个程序或函数的控制流和数据流,跨多个基本块进行优化。例如:全局常量传播、全局死代码消除等;
- 过程间优化(Interprocedural Optimization, IPO):涉及多个函数或过程,优化的范围超越单个函数的边界。例如:内联展开、过程间常量传播等。
中间代码优化属于机器无关,针对本地、全局和过程间都可以进行优化。下面介绍一些常见的优化方式,之后再使用LLVM进行优化实操。
① 常量折叠(Constant Folding)
预先计算常量表达式的结果,而不是在运行时计算。编译器会分析代码中的表达式,如果发现表达式完全由常量组成,编译器就会预先计算这个表达式的结果,并在生成的代码中用这个计算结果替换原有的表达式。这个过程不改变程序的语义,因为替换后的表达式和原表达式在逻辑上是等价的。例如:
int main() {
int a = 2 + 3;
int b = a * 10;
return b;
}
上述代码表达式 2 + 3 完全由常量组成,因此编译器在编译时就可以计算出它的结果为5。因此替换后生成:
int main() {
int a = 5;
int b = a * 10;
return b;
}
接着,虽然 a 不是一个字面常量,但是在上下文中它的值是已知的,因此表达式 a * 10 也可以在编译时被计算出结果为50。最终,代码可以被优化为:
int main() {
return 50;
}
② 死代码消除(Dead Code Elimination)
移除那些不会影响程序最终结果的代码。这种优化不仅可以减少程序的大小,还能提高执行效率,因为它减少了执行时的计算量和内存占用。死代码的类型有:
- 不可达代码:这类代码在任何情况下都不会被执行到。例如,在条件判断后的某个分支中,如果条件永远不会满足,则该分支中的代码就是不可达代码;
int func(int x) {
return x * 2;
printf("This line will never be executed.\n"); // 此行是死代码
}
- 无效果表达式:这类代码虽然会被执行,但是不会对程序的状态或输出产生任何影响。比如,对局部变量的赋值,如果这个局部变量之后没有被读取,那么这个赋值操作就是无效果的。
void example() {
int a = 10;
a = 20; // 这个赋值是死代码,因为a的值没有被使用
// 函数结束,没有任何对a的引用
}
③ 公共子表达式消除(Common Subexpression Elimination, CSE)
识别并消除在程序中多次计算的相同表达式,从而减少重复计算,提高程序的运行效率。这种技术识别在一段代码中多次出现的相同表达式,然后将这个表达式的计算结果保存在一个临时变量中,后续使用这个结果而不是重新计算表达式。举例:
int a = b * c + g;
int d = b * c * e;
上述代码b * c 被计算了两次。通过公共子表达式消除,我们可以将b * c的结果存储在一个临时变量中,然后复用这个结果:
int temp = b * c;
int a = temp + g;
int d = temp * e;
④ 循环展开(Loop Unrolling)
减少循环迭代次数,从而提高程序的执行效率。循环展开通过减少循环迭代次数来实现,它将循环体中的操作复制多份,每次迭代执行更多的工作,从而减少了循环控制逻辑(比如增量和条件测试)的开销。举例:
int sum = 0;
for (int i = 0; i < 100; i++) {
sum += array[i];
}
展开这个循环,每次迭代处理两个元素:
int sum = 0;
for (int i = 0; i < 100; i += 2) {
sum += array[i];
sum += array[i + 1];
}
⑤ 循环不变代码外提(Loop Invariant Code Motion)
将循环内部那些在每次迭代中都不会改变的计算移动到循环外部执行,从而减少了循环内部的计算量,提高了程序的效率。举例:
for (int i = 0; i < n; i++) {
if (b > 0) {
array[i] = b * array[i];
}
}
如果b的值在循环过程中不改变,那么if (b > 0)的判断结果是不变的。将这个判断移到循环外部,这样如果b小于等于0可以避免整个循环的执行:
if (b > 0) {
for (int i = 0; i < n; i++) {
array[i] = b * array[i];
}
}
⑥ 内联展开(Inline Expansion)
将函数调用替换为函数体本身的代码,以减少函数调用开销。这种技术的目的是减少函数调用时产生的额外成本,比如参数传递、栈帧创建和销毁等,从而提高程序的执行效率,也能提高局部性有助于缓存利用。举例:
int square(int x) {
return x * x;
}
int main() {
int sum = 0;
for (int i = 0; i < 10; i++) {
sum += square(i);
}
return sum;
}
内联展开后的代码如下,每次循环调用的square函数被替换成了它的函数体:
int main() {
int sum = 0;
for (int i = 0; i < 10; i++) {
sum += i * i; // 直接使用内联后的代码
}
return sum;
}
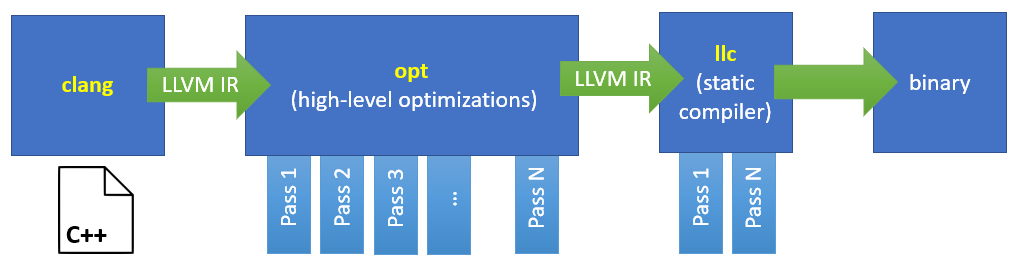
3. 优化LLVM中间代码
生成IR的命令可以直接带上优化参数生成优化后的结果:
# 带上 O2 参数来生成优化的 IR
clang -emit-llvm -S -O2 fun1.c -o fun1-O2.ll
另外还有一个单独的命令opt用来做代码优化。缺省情况下,它的输入和输出都是.bc 文件,带上 -S 参数则可以直接对.ll 文件进行优化。用 opt --help 命令,可以查看 opt 命令所支持的所有优化算法。
opt -O2 fun1.bc -o fun1-O2.bc
opt -S -O2 fun1.ll -o fun1-O2.ll
在 LLVM 内部,优化工作是通过一个个的 Pass(遍)来实现的,它支持三种类型的 Pass:
- 分析型的 Pass(Analysis Passes),只是做分析,产生一些分析结果用于后序操作;
- 代码转换的Pass(Transform Passes),比如做公共子表达式删除;
- 工具型的Pass,比如对模块做正确性验证。
个人也可以实现自定义Pass做一些扩展操作,更多Pass相关内容请阅读LLVM’s Analysis and Transform Passes。
对于前面生成的fun1.ll再执行代码优化操作,查看优化结果可以发现进行了“常量折叠”(执行优化命令前需要将fun1.ll 文件中的“optnone”这个属性去掉,它的意思是不进行代码优化)。